DOCUPIPE
Solutions
Resources
Pricing
DocuPipe vs Extend on 50 hard, real-world documents
Nitai Dean
Updated Jun 25th, 2026 · 11 min read
Table of Contents
- Why the difference between the two tests?
- The documents
- How we scored
- How to configure each system
- How we scored arrays
- Results
- The error profile matters as much as the score
- A closer look: a US oil and gas check stub
- A closer look: an air waybill
- What we are not claiming
- Two things Extend cannot do
- Reproduce it
- What to ask any benchmark
- FAQ
- Summary
DocuPipe vs Extend on 50 hard, real-world documents

DocuPipe and Extend are both intelligent document processing (IDP) tools. You give each one a document, a schema (meaning the list of fields you want to extract), and it reads the document and returns those fields as structured JSON. Both are AI-first: they use models to interpret a document rather than the hand-built, per-template rules that older extraction software relied on, so they generalize across layouts they were never set up for in advance. We run DocuPipe, and Extend is a direct competitor.
So: how do you tell two tools like these apart? On clean, single-page forms, most of them reach accuracies in the high nineties, so the headline metrics rarely separate them. The gap opens on the tougher documents, the ones you see in the real world. Things like invoice line items, multipage statements, payslips in non-Latin languages, and scanned or handwritten forms.
To test DocuPipe against Extend on those harder cases, we built a public benchmark of 50 hard documents, every one publicly available and sourced from the open web, and ran both systems on it. The set is deliberately messy: arrays and tables, eleven languages including right-to-left and CJK scripts, rotated scans, handwriting, and ten file types. We also ran both on Extend's own benchmark, RealDoc-Bench, so the comparison was not only on data we chose. The result? DocuPipe dominated on the hard set, and even eked out a victory on Extend's RealDoc-Bench.
The whole benchmark is public: the 50 documents, the hand-verified labels, the schema for each one, both engines' raw output, the scorer, and a link to every document's original source. You can rerun it yourself from the public benchmark repository on GitHub.
Explore the accuracy benchmarks in the interactive DocuBench explorer. It shows the same public results, with filters for language, file type, document length, and challenge type.
Results at a glance
Our hard public benchmark: DocuPipe 97.24% vs Extend 92.52%.
Extend's RealDoc-Bench QA: DocuPipe 95.31% vs Extend 95.15%.
Extend does well on flat field lookup, but DocuPipe's lead opens up once the documents get challenging: arrays, tables, multiple pages, multiple languages, rotated scans, and mixed file types. The full 50-document benchmark, including every label and both systems' raw output, is public on GitHub.
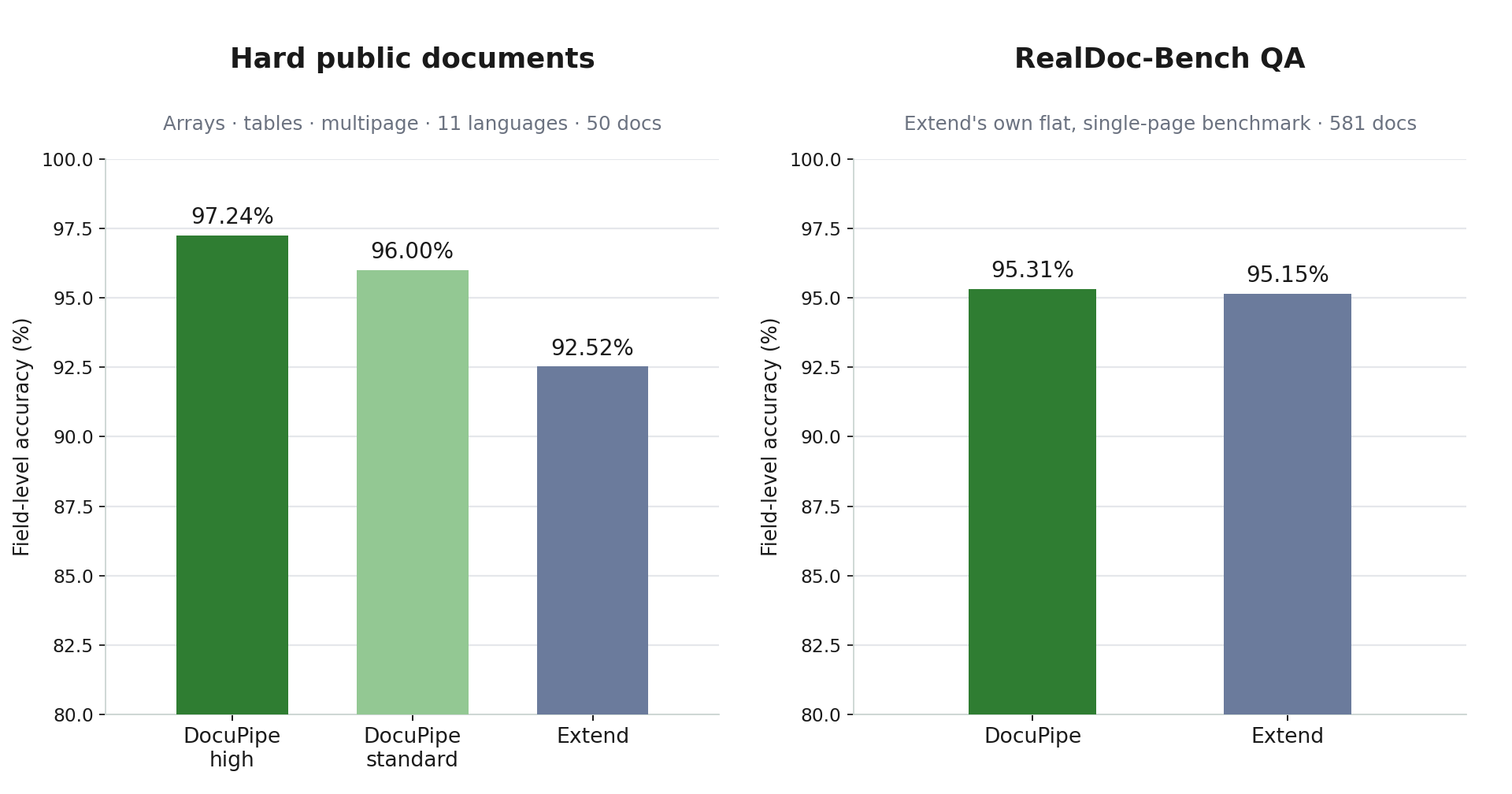 Two bar charts. Left: the hard public benchmark, where DocuPipe high (97.24%) and standard (96.00%) both lead Extend (92.52%). Right: Extend's own RealDoc-Bench QA, where DocuPipe (95.31%) and Extend (95.15%) finish within a fifth of a point of each other
Two bar charts. Left: the hard public benchmark, where DocuPipe high (97.24%) and standard (96.00%) both lead Extend (92.52%). Right: Extend's own RealDoc-Bench QA, where DocuPipe (95.31%) and Extend (95.15%) finish within a fifth of a point of each otherWhy the difference between the two tests?
A single accuracy number is not the full story, and doesn't reveal a crucial element: what kind of documents got tested. A benchmark of clean single-page forms only shows whether a system can find a few fields on a tidy page. That is the easy part of document extraction. The hard half is pulling 58 activity rows out of an 18-page brokerage statement, reading a right-to-left Hebrew payslip, and holding a table together across a page break.
This is why the RealDoc-Bench result matters as setup rather than as the headline. Extend published RealDoc-Bench, an open benchmark for real-world document parsing and question answering. It is a useful dataset, spanning hundreds of documents across finance, healthcare, mortgage, and supply chain - but it has limitations. Each document is only a single page, and the schemas are flat and primitive-only, with no nested objects and no arrays. That is a narrow slice of the real-world extraction problem, and only reflects one part of what users actually care about.
It is also Extend's own dataset, which cuts in their favor, not ours. They selected the documents and published the answer key, and we cannot rule out that their models were trained on these exact samples. So that narrow win is not the headline. It came on the other side's home field, on the kind of flat document where the real gap does not show. It is the result we wanted to establish before moving to the documents that do separate the two systems.
In real-world data and use cases, here is what shows up in practice:
- invoice line items
- bank and card transactions
- brokerage holdings and activity rows
- insurance coverage limits
- lab-result panels
- rent schedules
- bills of lading
- purchase-order rows
- utility charge tables
A tool that reads an invoice header but drops the line items is not ready for accounts payable. A tool that reads a brokerage statement but hallucinates extra activity rows is not ready for lending. So we built a second benchmark out of those cases.
The documents
The 50-document set is built to be hard on structure rather than hard on pixels. Every document is publicly available, and every label was authored for this benchmark and then checked by eye against the source.
| Documents | 50 |
| Languages | 11 (English, Hebrew, Japanese, Chinese, Arabic, French, German, Portuguese, Dutch, Italian, Spanish) |
| File types | 10 (PDF, JPEG, PNG, TIFF, XLSX, CSV, XML, TXT, DOCX, HTML) |
| Pages | 1 to 18 per document, 207 pages total |
| Structure | most documents carry at least one array, multipage, nested, or table feature |
Take this Japanese invoice. Thirty line items run down the page in vertical CJK, with product codes, unit prices, and a total that has to reconcile. A flat field-lookup benchmark doesn't address the complexity of this type of extraction.
 A Japanese tax invoice with thirty line items in a dense vertical table, product codes, quantities, unit prices, and a reconciling total
A Japanese tax invoice with thirty line items in a dense vertical table, product codes, quantities, unit prices, and a reconciling totalOr this Arabic tax invoice. It is right-to-left, with a charge array, VAT, and a grand total, all of which have to come back in the right order with the right labels.
 An Arabic right-to-left tax invoice with a multi-row charge table, VAT lines, and a grand total
An Arabic right-to-left tax invoice with a multi-row charge table, VAT lines, and a grand totalThe rest of the set is similar: a 32-row freight statement, a German balance sheet that has to reconcile to the cent, an engineering drawing with part numbers in small print, a handwritten field form, and a receipt shot at an angle on a wooden table.
We did not import labels from any public dataset, and we avoided the well-known ones (CORD, FUNSD, SROIE) on purpose, since a famous dataset is likely to sit in everyone's training data. We sourced fresh public documents instead: government filings, sample bills, public templates, vendor sample documents, public financial reports, and sample structured files. Neither system could have been trained specifically on this set, because the set did not exist before we built it.
Where DocuPipe, Extend, and our label disagreed, we treated it as a reason to audit ourselves first. If Extend returned an answer that was defensible under the schema, we fixed the schema or the label rather than scoring Extend down for our own ambiguity. That keeps the benchmark from collapsing into "our system versus our labels."
How we scored
Both engines ran the same way. We applied the same JSON schema to the same document through each system, then scored the returned JSON against the hand-verified label.
Accuracy is field-level. We count the leaf fields the system got right and divide by the total number of leaf fields in the label. If a label has 40 fields and the system gets 4 wrong, that is 90%. A field that is blank in both the label and the output is skipped rather than counted as a free match, so empty fields do not pad the score.
The two benchmarks used different scorers on purpose, because they are different tasks. For RealDoc-Bench we used the benchmark's structured gold answers with a deterministic equality scorer adapted to its answer format, after manually confirming that whitespace and punctuation normalization created no false matches. For the 50-document set we used DocuPipe's regular eval scorer, which is built for schema-shaped extraction.
How to configure each system
DocuPipe has a single setting that affects extraction: standard effort, or high effort. That's it. You pick standard by default, and for complex use cases, you pick high (if the results justify it).
In contrast to DocuPipe's simplicity, Extend exposes an entire configuration grid. You choose a parse engine, then an extract engine, then decide which add-on surcharges to stack on top, including an agentic OCR mode and a review agent, and there are marketed bundles like Performance Mode and a maxed-out everything-on mode. The combinations multiply quickly, and it is genuinely hard to know which one to run for a given document.
It also does not behave the way the names suggest. When we swept the grid, Extend's marketed Performance Mode and its everything-on mode both scored several points lower than a plainer configuration that their pricing tiers do not even surface. Turning on more add-ons made accuracy worse, not better.
So to keep the comparison fair, we did not run Extend on a default. We tried its settings, found the configuration that scored highest on average, and used that. Basically, we ran each platform at its best, and then compared the results.
How we scored arrays
A naive array scorer compares the first labeled row to the first returned row, the second to the second, and so on. That punishes a system for returning the right data in a different order, which is the wrong thing to penalize. Two systems can return the same 30 transactions in a different sequence and both be correct.
So our document scorer treats each array as a set of records and matches returned rows to labeled rows by best pairing before scoring their fields. Order does not count against either system. What counts is whether the rows, and the fields inside them, are right. Both engines are scored this exact same way, against the exact same labels.
Results
On the 50-document set, field-level accuracy was:
| System | Accuracy |
|---|---|
| DocuPipe high effort | 97.24% |
| DocuPipe standard effort | 96.00% |
| Extend | 92.52% |
DocuPipe runs at two effort levels. Standard is the default; high spends more compute per document. Both beat Extend here, so the lead does not depend on running the expensive tier.
Aggregate numbers flatten the story. On clean, simple forms both products often reach 100%. The 4.7-point gap is built on a handful of genuinely hard documents, and on those the gap is large.
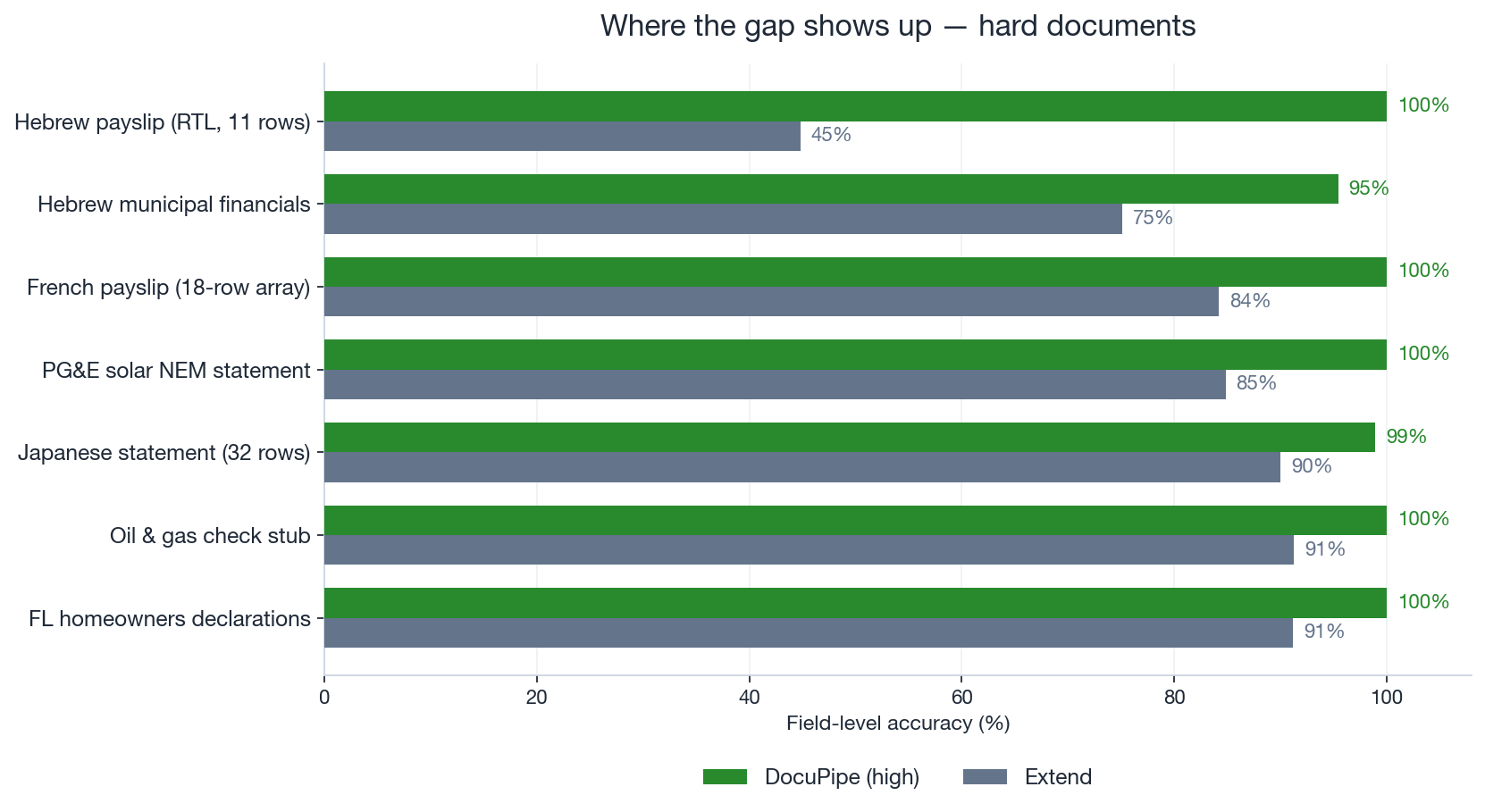 Horizontal bar chart comparing DocuPipe high effort and Extend on seven hard documents. DocuPipe sits at or near 100% on all of them, while Extend trails: 45% on a Hebrew payslip, 75% on Hebrew municipal financials, 84% on a French payslip, 85% on a PG&E solar statement, 90% on a Japanese statement, 91% on an oil-and-gas check stub, and 91% on a Florida homeowners declaration
Horizontal bar chart comparing DocuPipe high effort and Extend on seven hard documents. DocuPipe sits at or near 100% on all of them, while Extend trails: 45% on a Hebrew payslip, 75% on Hebrew municipal financials, 84% on a French payslip, 85% on a PG&E solar statement, 90% on a Japanese statement, 91% on an oil-and-gas check stub, and 91% on a Florida homeowners declarationThe Hebrew payslip is the clearest case. It is one page, right-to-left, with five payment rows and six deduction rows. Its amounts are printed in the Israeli convention where the last two digits are agorot (cents) and there is no decimal point: base pay prints as
1095000, meaning 10,950.00 shekels.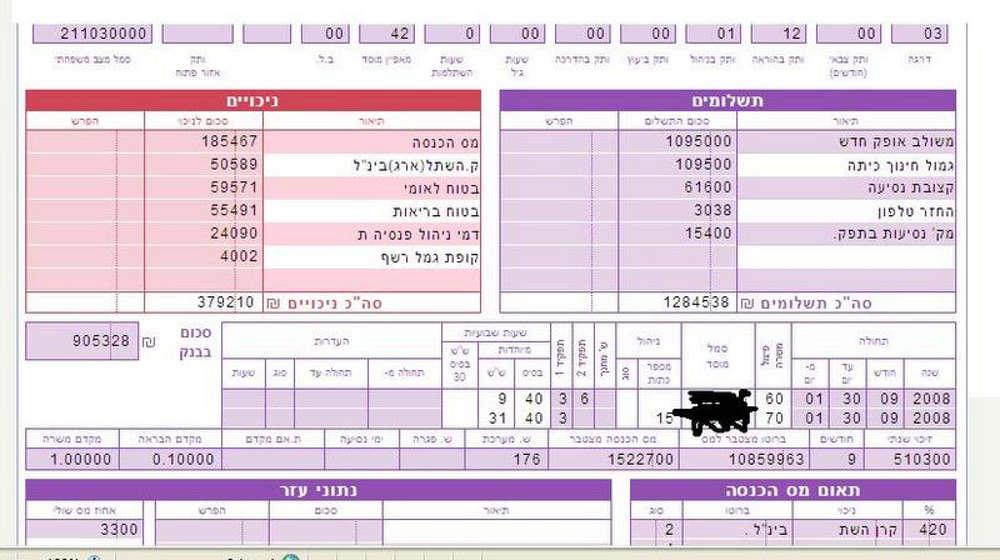 A real Hebrew payslip used in the benchmark, with right-to-left payment and deduction tables
A real Hebrew payslip used in the benchmark, with right-to-left payment and deduction tablesOn this single Hebrew payslip, DocuPipe scored 100% and Extend scored 44.8%. Both systems got the structure right: every payment and deduction row, every Hebrew label, in the correct order. The difference was the numbers. DocuPipe read the local convention correctly, turning
1095000 into 10,950.00 shekels; Extend returned the digits literally as 1,095,000. Every amount on the page is off by the same factor of a hundred:| Field | DocuPipe | Extend |
|---|---|---|
| Base pay | 10,950.00 | 1,095,000 |
| Education increment | 1,095.00 | 109,500 |
| Travel allowance | 616.00 | 61,600 |
| Income tax | 1,854.67 | 185,467 |
| National insurance | 595.71 | 59,571 |
| Health insurance | 554.91 | 55,491 |
| Total payments | 12,845.38 | 1,284,538 |
| Net to bank | 9,053.28 | 905,328 |
DocuPipe matches the hand-verified label on every row; Extend made the identical error on all eleven line items and every total.
Both engines saw the exact same schema, and neither was told about the convention. But there is only one correct reading: the payment rows minus the deduction rows equal the printed net pay. DocuPipe inferred that from the document, and Extend did not. On a payslip, that is the difference between ₪10,950 and ₪1,095,000 landing in a payroll run. These are exactly the kind of real-world "gotchas" that separate the good extractors from the great ones. The ability to just get it right.
The same pattern repeats across the hard cases.
Multilingual and right-to-left. Hebrew, Japanese, Chinese, Arabic, and the European languages all stress reading order, field naming, and local number formats. Extend's French payslip dropped to 84% and its Hebrew municipal financials to 75%, while DocuPipe stayed at or near 100%.
Array-heavy. Line items, transactions, holdings, coverage limits, charges, and lab results all require returning complete, correctly-ordered records rather than isolated values. This is where over-inclusion and dropped rows corrupt a result.
Multipage and cross-page. Statements, contracts, and financial reports force the extractor to carry context across page boundaries instead of treating each page on its own.
Beyond PDF. Spreadsheet, CSV, XML, TXT, DOCX, HTML, TIFF, and PNG inputs, because real pipelines stopped being PDF-only a long time ago.
The error profile matters as much as the score
The RealDoc-Bench score was the less interesting half of that benchmark - the error profile was the interesting part: DocuPipe tends to be conservative. When it misses, it is usually because a character or token was read or split incorrectly. Extend tends to be looser. Its misses skew toward over-inclusion, where extra nearby text gets appended to a value, and hallucination, where a value appears even though the field on the document is empty.
That difference matters in production. A conservative miss is easy to catch on review. An invented value looks exactly like a real one and flows straight downstream into an ERP, an underwriting model, or a ledger. The next two documents show a real instance of each: a fabricated value in a blank cell, and an over-inclusion error that splits one field across two.
A closer look: a US oil and gas check stub
Aggregate percentages are easy to wave away, so here is a single English document where you can read the right answer off the page yourself.
This is the line-item table from a Samson Energy oil and gas revenue check stub. Two property rows, each with its own unit price, volumes, taxes, and a column of itemized deductions.
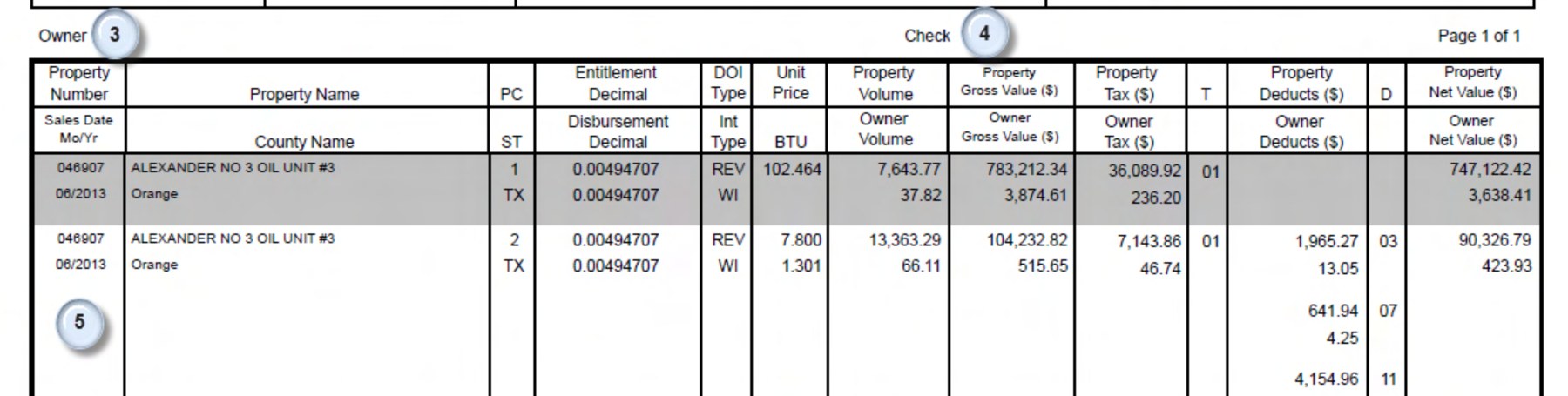 The line-item table from an oil and gas check stub, showing two property rows with separate Unit Price and BTU columns and a multi-line Owner Deducts column
The line-item table from an oil and gas check stub, showing two property rows with separate Unit Price and BTU columns and a multi-line Owner Deducts columnRead the gas row, product code 2. The document prints a Unit Price of 7.800 and a BTU of 1.301 in two separate columns. Its owner deductions are three itemized lines that add up to 44.98. The oil row above it has an empty owner-deductions cell. Here is what each system returned:
| Field | What the document shows | DocuPipe | Extend |
|---|---|---|---|
| Gas row, unit price | 7.800 | 7.80 ✓ | 1.301 ✗ (copied the BTU column) |
| Gas row, owner deductions | 13.05 + 4.25 + 27.68 = 44.98 | 44.98 ✓ | 13.05 ✗ (took only the first of three lines) |
| Oil row, owner deductions | (blank on the document) | (left blank) ✓ | 0 ✗ (invented a value) |
Three different failure modes on one small table. Extend pulled a number from the wrong column, returned an incomplete sum from a multi-line cell, and filled a blank field with a fabricated
0. On a revenue statement, each of those is a wrong dollar figure that looks legitimate downstream.A closer look: an air waybill
The same pattern shows up on this Ethiopian Airlines air waybill. Look at the consignee box. The organization name runs onto a second line, and the address starts at "RAS DESTA DAMTEW AVENUE".
 The consignee box of an air waybill, where the organization name THE SECRETARY GENERAL ETHIOPIA RED CROSS SOCIETY wraps onto a second line before the street address begins
The consignee box of an air waybill, where the organization name THE SECRETARY GENERAL ETHIOPIA RED CROSS SOCIETY wraps onto a second line before the street address begins| Field | What the document shows | DocuPipe | Extend |
|---|---|---|---|
| Consignee name | THE SECRETARY GENERAL ETHIOPIA RED CROSS SOCIETY | "THE SECRETARY GENERAL ETHIOPIA RED CROSS SOCIETY" ✓ | "THE SECRETARY GENERAL ETHIOPIA" ✗ (dropped the second line) |
| Consignee address | RAS DESTA DAMTEW AVENUE, P.O.BOX 195, ADDIS ABABA... | "RAS DESTA DAMTEW AVENUE, P.O.BOX 195, ADDIS ABABA..." ✓ | "RED CROSS SOCIETY RAS DESTA DAMTEW AVENUE..." ✗ (absorbed the name's second line) |
Extend split the consignee at the line break, cut the organization name in half, and pushed "RED CROSS SOCIETY" into the address. The name and the address are now both wrong. This is the over-inclusion failure in miniature, and it is the kind of boundary error a flat single-line benchmark never surfaces.
What we are not claiming
No extraction system wins on every document, and this benchmark does not show one that does.
On clean, single-language, structured documents, both products frequently hit 100%. More than 20 documents in the set are a tie at the top. The 4.7-point gap comes from the hard cases, not from a broad advantage on easy ones.
DocuPipe is not perfect on the hard cases either. On an engineering drawing with part numbers printed in a worn stencil font, both systems trusted bad OCR and scored in the 70s and 80s. That is an OCR-fidelity problem, not a structure problem, and it is the slice where the two products look most alike.
Extraction is also not perfectly repeatable. The underlying models are non-deterministic, so a given document's score can move by a few points between runs. The aggregate is stable across runs; individual documents can move.
Finally, we do not lean hard on the RealDoc-Bench number. As noted above, it is Extend's own dataset and the home-field advantage runs their way, so we treat that narrow win as setup, not as the headline. The result we stand behind is the 50-document set, built from documents neither side had seen before.
Two things Extend cannot do
Two of Extend's limits are about what it can take in and represent, not about accuracy:
- It does not accept JSON as an input file. A
.jsonupload is rejected, where DocuPipe extracts from JSON directly. - Its schema cannot represent an array of plain strings. Every array item has to be an object, so a simple list, like a set of diagnosis names or the bullet points in an HTML document, has to be wrapped in objects rather than returned as a flat list.
We designed around both so that all 50 documents run on both engines and the comparison stays apples to apples, and we did not let either count against Extend's score. They are still real constraints if your inputs are JSON or your fields are plain string arrays.
Reproduce it
The 50-document benchmark is public, on GitHub. The repository contains the source documents, the hand-verified labels, the schema applied to each document, both engines' raw extraction output, the scorer, and a full source manifest with the license for every document. The scorer reproduces the aggregate numbers in this post from the committed results. Where a public source is verified but the underlying form carries separate copyright, we link to the public source rather than redistribute the file.
You don't need to clone the repo to dig in: the interactive DocuBench explorer presents the same results document by document, filterable by language, file type, length, and challenge type.
What to ask any benchmark
When you evaluate a document extraction tool, do not stop at the headline accuracy. Ask what the benchmark is made of:
- Single page or multipage?
- Arrays and repeated records, or just isolated fields?
- Tables that span pages?
- Non-English documents?
- Rotated scans and phone photos?
- File types beyond PDF?
- Are blank fields tested for fabrication?
- Are labels hand-verified, and are disagreements audited or just assumed correct?
Those questions decide the outcome. On a flat field-lookup benchmark, DocuPipe and Extend are nearly tied. On a benchmark built from the documents that carry real business data, the gap is plain.
FAQ
No. The first benchmark, RealDoc-Bench, is Extend's, on Extend's public documents and Extend's answer key, and we still came out slightly ahead. The second benchmark is ours, but every document in it is public, and every label was audited so that defensible Extend answers fixed our schema instead of scoring Extend down. Both sets are inspectable.
Because those are private customer files. Sending them to a competitor would mean shipping real customer data out, and it would not be a benchmark anyone else could inspect. Building the hard set from public documents keeps it both private-safe and reproducible.
They are two effort levels on the same DocuPipe extraction. Standard is the default. High effort spends more compute per document and is the lever for genuinely hard inputs. On the hard benchmark, standard already beat Extend, and high effort widened the gap.
No, and no extraction system does. On clean, simple forms both products frequently hit 100%. The claim is narrower: when the task shifts from flat field lookup to preserving structure across hard, multilingual, multipage documents, DocuPipe's lead is clear and consistent.
Summary
Two public head-to-head benchmarks, same conclusion.
On Extend's RealDoc-Bench QA dataset, DocuPipe scored 95.31% and Extend's best configuration scored 95.15%. A narrow win, by 6 fields out of 3,753.
On our 50-document public benchmark of hard, structured, multilingual documents, DocuPipe scored 97.24% and Extend 92.52%.
Flat field lookup is a solved-enough problem that many systems look good on it. The moment a document has structure worth preserving is where extraction quality starts to matter, and where the gap shows.
Recommended Articles
Related Documents
Related documents:
Related documents:
Check
Invoice
RIB
Utility Bill
CT-e
Non-Disclosure Agreement
NF-e
Balance Sheet
Air Waybill
Receipt
Tax Invoice
Tax Invoice
BAS
NDA
Request for Information
+