The Human-in-the-Loop (HITL) Escalation Protocol
DocuPipe Team
Updated Mar 27th, 2026 · 12 min read
Table of Contents
The Human-in-the-Loop (HITL) Escalation Protocol
Every document AI vendor promises high accuracy. Some claim 99%. Others imply near-perfection. These claims collapse under scrutiny.
What does 99% accuracy mean when processing 100,000 documents? It means 1,000 errors. If those documents are financial filings, that is 1,000 potential misstatements. If they are healthcare records, that is 1,000 potential patient safety issues. If they are government benefits applications, that is 1,000 people potentially denied or incorrectly granted benefits.
For regulated industries, the question is not whether AI will make errors. The question is whether those errors will be caught before they cause harm. Human-in-the-loop processes provide this safety net when designed correctly.
What You Need to Know
The math problem: 99% accuracy sounds great until you do the math. With 20 fields per document and 10,000 documents monthly, that's ~1,650 documents with at least one error. Every month.
The real question: Not "will AI make errors?" but "will errors be caught before they cause harm?"
The solution: Confidence-based routing. High confidence (~95%+) proceeds automatically. Medium confidence gets flagged. Low confidence requires human review. You're not reviewing everything - just the uncertain stuff.
Bottom line: HITL isn't a failure of AI. It's what makes AI actually usable in regulated environments.
For the broader context on enterprise document AI infrastructure, see the Enterprise Document AI Infrastructure hub article. For how confidence scores and bounding boxes enable verification, see Preventing AI Hallucinations with Visual Review.
The Myth of 100% Automation in High-Risk Environments
The appeal of full automation is obvious: eliminate human labor costs, process documents instantly, scale without hiring. The appeal is also a trap.
Error Rate Mathematics
Consider a document AI system with 98% field-level accuracy. This sounds excellent. In production:
Per document:
- Average 20 fields per document
- 98% accuracy means 2% error rate
- Expected 0.4 field errors per document
- For 20 fields, probability of at least one error is ~33%
At scale:
- 10,000 documents per month
- ~3,300 documents with at least one error
- ~8,000 individual field errors
Even 99% accuracy produces ~1,650 documents with errors monthly. 99.5% still yields ~825 problematic documents.
These are not hypothetical concerns. They are mathematical certainties given known accuracy rates.
Error Distribution Challenges
Errors are not distributed uniformly:
Document type variation:
Some document types process reliably. Others produce consistent failures. A 98% overall rate might reflect 99.9% on standard invoices and 85% on handwritten forms.
Field type variation:
Some fields extract reliably (dates in standard formats). Others fail consistently (long text in poor handwriting). Overall accuracy obscures field-specific weaknesses.
Temporal variation:
Accuracy can degrade over time as document populations shift. A system trained on 2023 forms may struggle with 2025 redesigns.
Error clustering:
When one field fails, related fields often fail too. A misidentified table affects all cells within it. Error independence assumptions are violated.
Regulatory Realities
Regulations do not accept accuracy percentages as compliance:
Healthcare (HIPAA, HITECH):
Patient records must be accurate. Systematic errors in extraction could affect treatment decisions. The fact that "most records are correct" does not protect the patients harmed by incorrect ones.
Government (various):
Benefits determinations must be accurate for each applicant. Statistical accuracy is irrelevant to individuals incorrectly denied or granted benefits.
Full automation that produces even small error rates may be non-compliant in regulated contexts.
How Chain-of-Thought Reasoning Improves Extraction
Chain-of-thought (CoT) prompting improves LLM reasoning by having the model explain its logic before producing answers. For document processing, structured reasoning approaches can improve reliability and auditability.
Standard CoT Limitations
Unrestricted chain-of-thought has problems for enterprise use:
Unpredictable length:
The model may produce extensive reasoning for simple extractions or minimal explanation for complex ones. Processing time and cost vary unpredictably.
Irrelevant reasoning:
The model may explore tangential considerations unrelated to the extraction task. Reasoning does not focus on what matters.
Inconsistent structure:
Reasoning format varies between documents and even fields. Parsing and auditing become difficult.
Hallucinated confidence:
The model may express high confidence in its reasoning even when that reasoning is flawed. Confidence in CoT output does not correlate reliably with accuracy.
Structured Reasoning Approach
Constraining reasoning within a defined framework improves consistency:
Step 1: Evidence identification
The model identifies specific text regions that inform the extraction:
EVIDENCE for invoice_total:
- Found "$12,450.00" at page 1, line 47
- Preceded by "TOTAL DUE:" label
- Appears in standard invoice total position
Step 2: Interpretation
The model explains how evidence maps to the field:
INTERPRETATION:
- Label "TOTAL DUE:" indicates this is the final amount
- Format matches currency (dollar sign, comma, decimal)
- Position at bottom of line items confirms total
Step 3: Confidence assessment
The model evaluates extraction reliability:
CONFIDENCE: HIGH
- Evidence clearly labeled
- Single unambiguous value
- Standard format and position
Step 4: Extraction
The final extraction with structured metadata:
EXTRACTION:
- Field: invoice_total
- Value: 12450.00
- Type: currency
- Confidence: 0.95
Benefits of Structured Reasoning
This structured approach provides specific advantages:
Predictable processing:
Fixed reasoning structure produces consistent processing time and cost. Budgeting and capacity planning are reliable.
Focused reasoning:
Evidence must be cited specifically. Interpretation must connect evidence to extraction. Reasoning stays on task.
Auditable decisions:
Each extraction includes its justification. Auditors can review reasoning, not just results. Error patterns are identifiable.
Calibrated confidence:
Confidence is based on explicit criteria (evidence clarity, format match, position). Scores correlate better with actual accuracy.
Learning from errors:
When extractions are corrected, the reasoning record shows where interpretation failed. Improvements target actual failure modes.
Confidence-Based Routing and Review
 DocuPipe visual review interface showing human-in-the-loop workflow
DocuPipe visual review interface showing human-in-the-loop workflowHuman review is expensive. Confidence-based routing minimizes review volume while ensuring uncertain extractions receive human attention.
Confidence-Based Routing
 Form confidence visualization showing field-level scores
Form confidence visualization showing field-level scoresEvery extraction produces a confidence score. Routing thresholds determine processing path:
Tier 1: Automatic processing (~95%+ confidence)
- Extraction proceeds without human review
- Results flow directly to downstream systems
- Audit log records automatic approval
- Sampling-based verification catches systematic issues
Tier 2: Flagged processing (~80-95% confidence)
- Extraction proceeds but is marked for potential review
- Results are tagged as provisionally approved
- Review queue receives batch of flagged items
- Human reviewer confirms or corrects in batches
Tier 3: Mandatory review (below ~80% confidence)
- Extraction flagged for human review
- Reviewer sees AI extraction alongside source document
- Correction or confirmation recommended before downstream use
- Corrected extractions feed model improvement
Field-Level Routing
Confidence thresholds can vary by field criticality:
High-criticality fields:
- Financial amounts with material impact
- Patient identifiers affecting treatment
- Legal terms affecting contract interpretation
- Any field where errors cause significant harm
These fields require higher confidence for automatic processing.
Medium-criticality fields:
- Reference numbers and identifiers
- Dates and timestamps
- Status and category fields
- Fields where errors cause operational inconvenience
Standard thresholds typically apply.
Low-criticality fields:
- Optional descriptive fields
- Comments and notes
- Metadata with limited downstream impact
- Fields where errors are easily corrected later
These may process automatically at lower confidence levels.
Review Interface Design
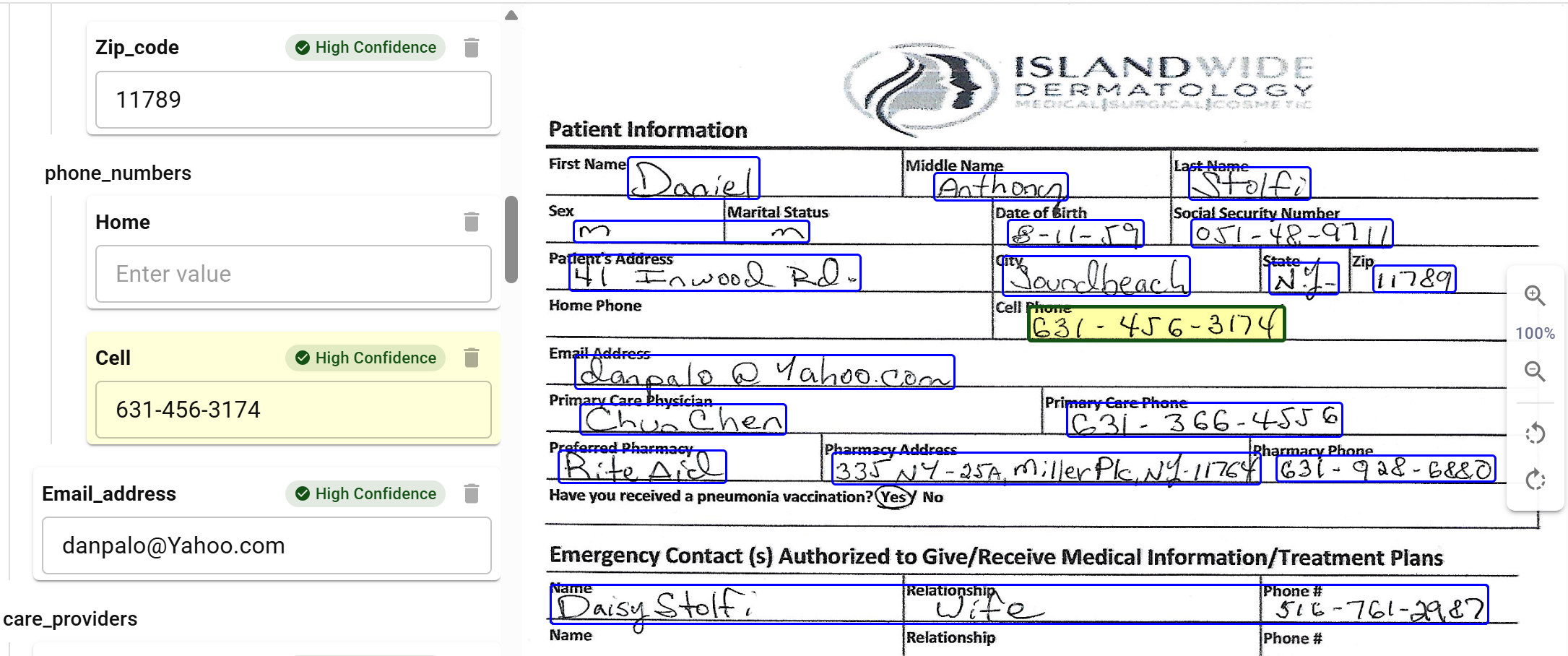 Visual review showing healthcare form with extracted fields and confidence indicators
Visual review showing healthcare form with extracted fields and confidence indicatorsHuman review efficiency depends on interface design:
Side-by-side display:
- Source document on one side
- Extracted data on the other
- Automatic scroll synchronization
- Zoom controls for detail examination
Highlighting:
- Bounding boxes show extraction source regions
- Color coding indicates confidence levels
- Click on field to jump to source location
- Multiple evidence regions displayed
Efficient correction:
- Edit in place for corrections
- Dropdown for enumerated fields
- Date pickers for date fields
- Keyboard shortcuts for common actions
Batch processing:
- Multiple documents in review session
- Consistent interface across document types
- Progress tracking and session management
- Break reminders for sustained reviewing
Escalation Paths
Some situations require escalation beyond standard review. DocuPipe's review interface supports building escalation workflows for scenarios like:
Subject matter expert escalation:
- Domain-specific terminology requiring expertise
- Unusual document formats not covered by training
- Ambiguous situations requiring interpretation
- Policy questions about extraction rules
Supervisor escalation:
- Patterns of reviewer disagreement
- Documents with regulatory significance
- Customer disputes about extraction
- Quality issues requiring process changes
Exception handling:
- Documents that cannot be processed
- Corrupted or illegible source materials
- Missing information requiring source clarification
- System errors during processing
Organizations can configure triggers and routing rules based on their specific needs.
Quality Metrics
Escalation effectiveness requires monitoring:
Automation rate:
- Percentage of extractions processed automatically
- Trend over time (should improve)
- Breakdown by document type and field
- Comparison to targets
Review accuracy:
- Percentage of flagged items that reviewers change
- False positive rate (flagged but correct)
- False negative rate (not flagged but incorrect)
- Reviewer agreement rates
Cycle time:
- Time from document receipt to completed extraction
- Time spent in each processing stage
- Review queue depth and wait times
- SLA compliance rates
Cost metrics:
- Cost per document by processing path
- Review cost as percentage of total
- Trend in review requirements
- ROI compared to full manual processing
Continuous Improvement
Escalation protocols improve through feedback:
Correction analysis:
- Which fields are corrected most often?
- Which document types require most review?
- Are corrections clustered or random?
- Do corrections suggest threshold adjustments?
Threshold optimization:
- Fields with few corrections may tolerate lower thresholds
- Fields with many corrections need higher thresholds
- A/B testing of threshold changes
- Gradual adjustment with monitoring
Model improvement:
- Corrections become training examples
- Retrained models reduce error rates
- Reduced errors enable higher automation
- Virtuous cycle of improvement
Process refinement:
- Review interface improvements based on feedback
- Escalation path optimization
- Quality metric target adjustments
- Documentation updates
Implementation Considerations
Deploying HITL processes requires organizational readiness beyond technology:
Staffing and Training
Human reviewers need:
- Understanding of document types being processed
- Training on extraction schemas and field definitions
- Proficiency with review interface
- Awareness of common error patterns
- Guidelines for escalation decisions
Staffing models must account for:
- Volume variation (peak periods)
- Coverage requirements (business hours, 24/7)
- Reviewer fatigue and rotation
- Quality assurance sampling
SLA Definition
Service level agreements should specify:
- Maximum time to completed extraction by priority
- Review queue depth limits
- Escalation response times
- Quality targets and measurement
- Remediation procedures for SLA misses
Change Management
Organizations accustomed to either full manual processing or attempted full automation need adjustment:
- Hybrid models require different workflows
- Reviewer roles differ from data entry roles
- Automation trust must be earned gradually
- Metrics shift from volume to quality
Key Takeaways
- 99% accuracy still means thousands of errors at scale - do the math before trusting vendor claims
- HITL isn't a failure of AI - it's what makes AI actually usable in regulated environments
- Confidence-based routing minimizes review - you're not reviewing everything, just the uncertain stuff
- Field-level thresholds focus attention - high-impact fields get stricter thresholds
- Good review interfaces matter - side-by-side display, bounding boxes, keyboard shortcuts
See how DocuPipe handles human-in-the-loop review.
Even 99% field-level accuracy produces errors at scale. With 20 fields per document and 10,000 documents monthly, 99% accuracy means approximately 1,650 documents with at least one error. Regulations do not accept accuracy percentages as compliance. Each incorrect patient record, financial misstatement, or benefits determination affects real people and creates regulatory exposure.
Structured reasoning approaches constrain LLM output within a defined framework: evidence identification (citing specific text regions), interpretation (explaining how evidence maps to fields), confidence assessment (evaluating reliability), and extraction (producing structured output). This produces more predictable processing time, focused reasoning, and better-calibrated confidence scores.
Extractions above ~95% confidence proceed automatically. Extractions between ~80-95% are flagged for batch review. Extractions below ~80% require mandatory review before proceeding. Field-level thresholds vary by criticality. High-impact fields require higher confidence for automatic processing.
Recommended Articles
Related Documents