DOCUPIPE
Solutions
Resources
Pricing
Extract data from Hebrew, Arabic, and 300+ other languages
Most extraction tools are built English-first and fall apart on non-Latin scripts and right-to-left text. DocuPipe reads documents in 300+ languages and scripts, handles Hebrew and Arabic right-to-left with the layout intact, and returns the same structured data no matter the language.
The problem
Why this is hard to automate
English-first tools choke on non-Latin scripts
Most document tools were trained on English and other Latin-script text. Point them at Hebrew, Arabic, Chinese, or Cyrillic documents and accuracy drops, characters get mangled, or whole sections come back empty.
Right-to-left text comes back scrambled
Naive OCR reads left-to-right regardless of the language. On Hebrew and Arabic that reverses words, misplaces punctuation, and jumbles numbers, so the extracted text is unusable before you even get to structuring it.
How it works
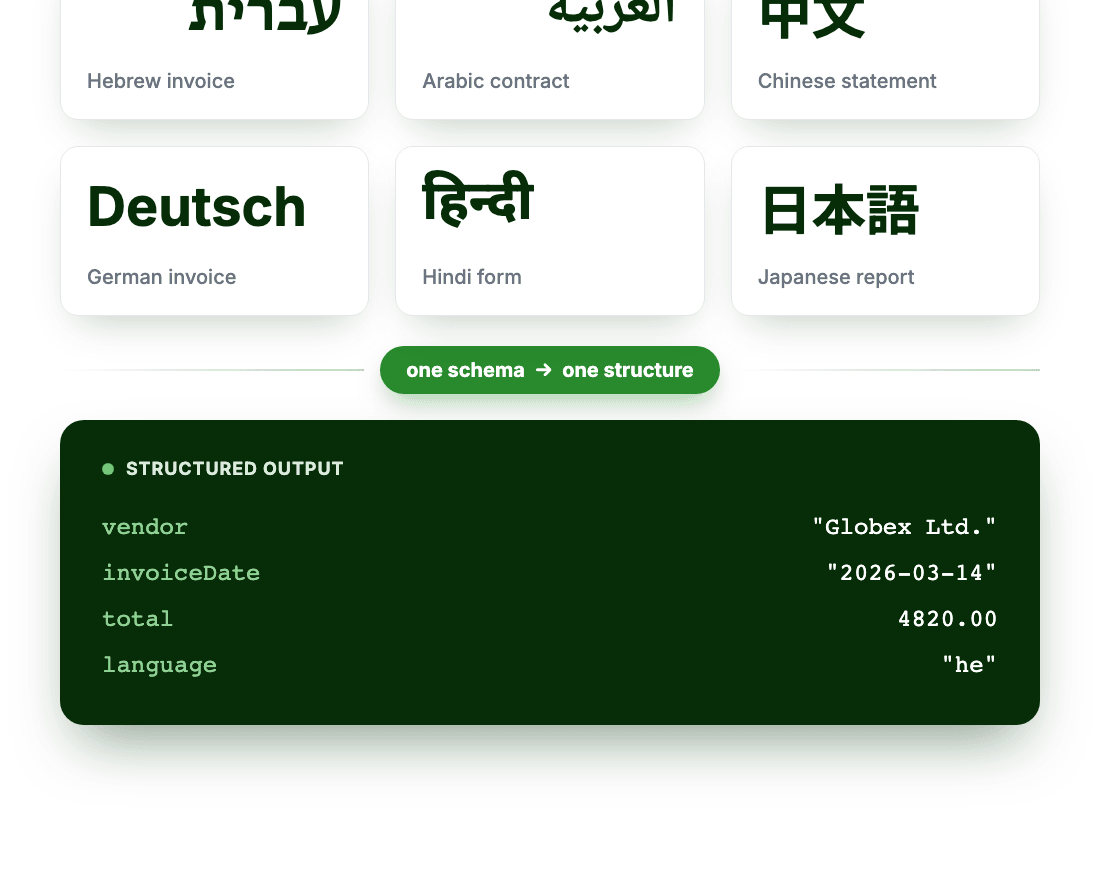
Define the schema once. Run it on any language.
Your schema describes what the fields mean, not what language the document is in. DocuPipe detects the language, reads the text in the correct direction, and fills the same fields whether the source is in Hebrew, Arabic, German, or Japanese.
Describe the fields in English
Define vendor, date, total, parties, or any other fields once. The schema is language-independent, so you don't build a separate one per language.
Upload documents in any language
Hebrew invoices, Arabic contracts, Chinese statements, German forms. DocuPipe detects the language and reads right-to-left scripts in the correct order, with the layout preserved.
Get one consistent structure back
The same structured JSON or CSV for every document, with the detected language tagged on the output, ready to load into systems that expect one schema.
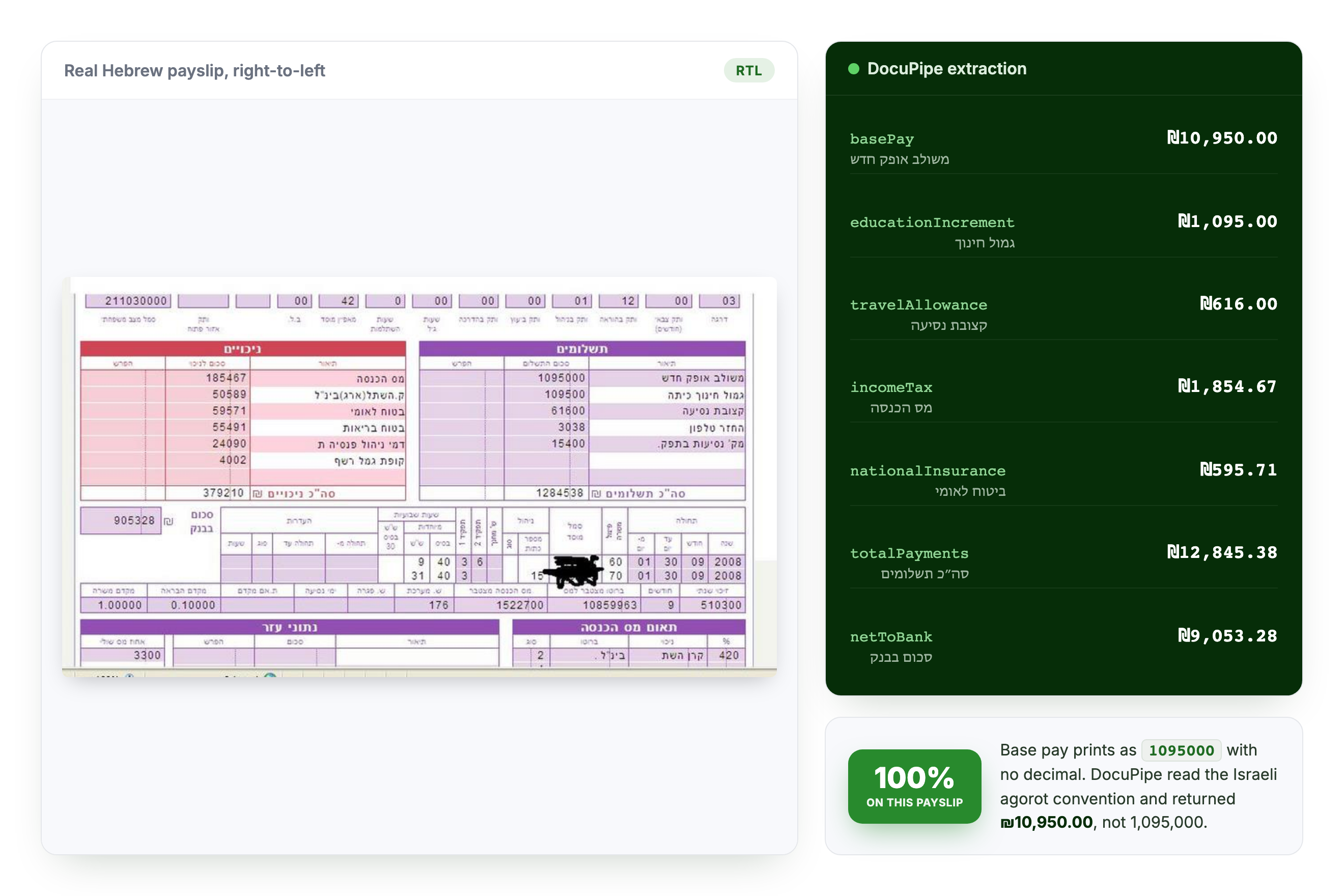
A real Hebrew payslip from our public benchmark: DocuPipe read the Israeli agorot convention and scored 100% on it.
Document types
Document types we read across languages
Invoices in any language
Vendor invoices and receipts in Hebrew, Arabic, German, Chinese, and more, mapped to one set of fields regardless of language.
Contracts & legal documents
Agreements, powers of attorney, and incorporation documents in non-English and right-to-left scripts.
IDs & government documents
Identity documents, civil records, and government forms issued in local languages and scripts.
Financial statements & reports
Bank statements, annual reports, and filings produced in the local language of each market.
Medical & academic records
Lab reports, study booklets, and records in Hebrew, Arabic, and other languages, structured into consistent fields.
Shipping & trade documents
Bills of lading, customs forms, and export paperwork that cross borders and languages in a single batch.
Why DocuPipe
Built for speed, scale, and accuracy
languages and scripts read out of the box, including Latin, Cyrillic, CJK, Arabic, Hebrew, Devanagari, and Thai
Hebrew and Arabic read right-to-left, with reading order and layout preserved
field-level accuracy on printed text across scripts, verifiable with human review
language detected per document, so you never set a locale or pick a language up front
Live Demo
See it in action
Try one of our sample documents or upload your own
Sample Document
bank-statement-chequing.png
PNG FILE
bank-statement.pdf
PDF FILE
cloudinary.pdf
PDF FILE
credit-card-statement.jpg
JPG FILE
jetbrain.png
PNG FILE
sendgrid.pdf
PDF FILE
Upload your own
Drag a document to the drop zone to get structured results.
Drop document here
Drag a sample from the left or upload your own to see how we standardize it.
Who this is for
Teams that put this on autopilot
Global operations teams
Process documents from every market you operate in without a separate tool or workflow per language. One schema covers them all.
Teams in non-English markets
Work natively in Hebrew, Arabic, or any local language. Get structured data from documents in your own market instead of forcing everything through English-first tooling.
Software builders
Embed extraction that handles whatever language your users upload, so your product works the same in every region without per-language engineering.
Security & compliance
Enterprise-grade security you can trust

SOC 2 Type II
SOC 2 reports are available through our trust center.

ISO 27001
ISO 27001 certification is part of our security program.

GDPR
Paid teams can select Europe as their storage region for new uploads.
Frequently asked questions
Our OCR engine reads 300+ languages and scripts out of the box, including Latin, Cyrillic, CJK (Chinese, Japanese, Korean), Arabic, Hebrew, Devanagari, and Thai. For the vast majority of use cases, language coverage is effectively unlimited. The language of each document is detected automatically, so you never have to set a locale up front.
Yes. DocuPipe reads right-to-left scripts in the correct reading order and preserves the spatial layout of the page, so Hebrew and Arabic text comes back correctly ordered rather than reversed or jumbled. Printed Hebrew and Arabic extract reliably.
Yes. A schema describes what the fields mean, not what language the document is in. You define your fields once in English and run that same schema across documents in any supported language, getting one consistent structure back every time.
Printed text extracts strongly across scripts. Handwriting works too, but quality varies by script and legibility, and is harder for non-Latin handwriting than for printed text. If your documents are handwritten, test on a representative sample first to see the results on your specific content before committing to volume.
DocuPipe is SOC 2 Type II certified, ISO 27001 certified, and HIPAA compliant. Paid teams can choose Europe as their storage region for new uploads, and stored data is encrypted at rest and in transit.
Get up to 20k free credits by signing up