DOCUPIPE
Solutions
Resources
Pricing
Extract data from documents that never look the same twice
Every vendor, every form, every scan is laid out differently - and template-based tools break on the first one they haven't seen. DocuPipe reads documents the way a person does, so one schema works across every layout. No templates, no rules, no per-vendor setup.
STRUCTURED OUTPUT
When AWS Textract couldn't handle their varied documents, DocuPipe could
“Data entry was our limiting factor to growth. We tried AWS Textract and it couldn't handle our documents. DocuPipe turned hundred-page batches of wildly different layouts into clean, structured data ready for federal upload.”
The problem
Why this is hard to automate
Templates break the moment the layout changes
Position-based and template tools assume a field is always in the same spot. The instant a vendor reformats, a new supplier sends a different form, or a scan is rotated, the extraction silently fails - and someone has to notice, debug, and rebuild the template.
You can't pre-build a template for every layout
When documents come from hundreds of sources - invoices from every vendor, forms from every counterparty - the template approach doesn't scale. You'd spend more time maintaining templates than processing documents.
How it works
One schema. Any layout. Zero templates.
Instead of telling the system where a field is, you tell it what the field means. DocuPipe's models understand document structure, so the same schema extracts cleanly whether the document is a crisp PDF, a phone photo, or a layout you've never encountered.
Describe the fields once
Define what you want in plain language - vendor name, total, line items, dates. You never reference positions, coordinates, or layouts. This is the only setup.
Throw any document at it
Clean PDFs, crooked scans, photos, mixed-format batches from a hundred different sources. DocuPipe reads each one on its own terms - no per-layout configuration.
Get the same clean output every time
Structured JSON or CSV with the fields you asked for, plus confidence scores and source citations - identical shape regardless of how the input was laid out.
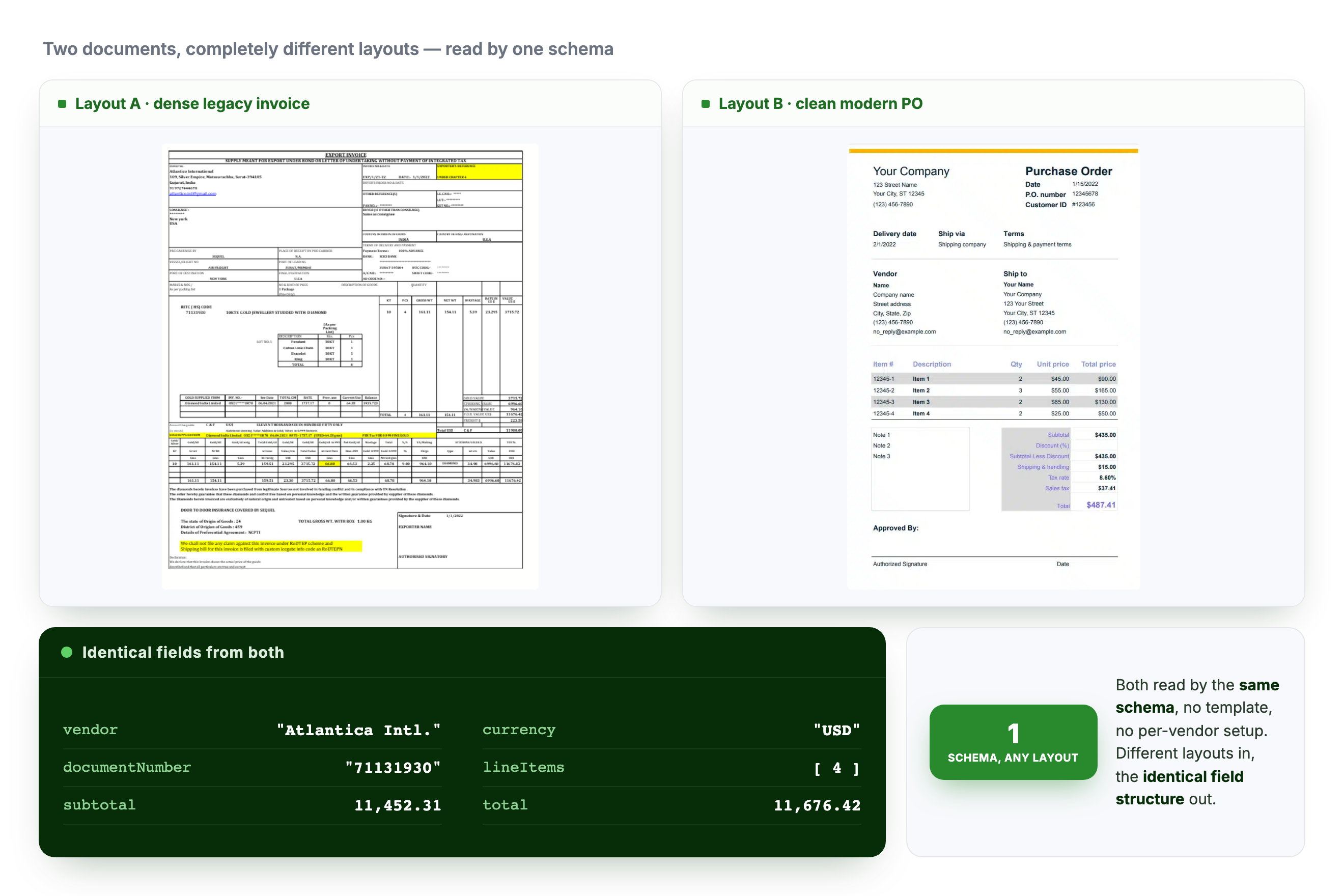
The same schema reads a dense legacy invoice and a clean modern PO into the identical field structure.
Document types
Built for the messy reality of real documents
Invoices from any vendor
Every supplier formats invoices differently. One schema pulls vendor, totals, and line items across all of them - no per-vendor template.
Purchase orders & bills of lading
Mixed batches of POs, export invoices, and shipping docs in wildly different layouts, extracted into one consistent structure.
Forms & applications
Intake forms, applications, and questionnaires that differ by source, including handwritten fields and check boxes.
Statements & reports
Bank statements, financial reports, and statements whose layout changes by institution and reporting period.
Contracts & agreements
Leases, NDAs, and service agreements where the same clause sits in a different place in every document.
Scans & photos
Rotated, skewed, low-quality scans and phone photos, handled by agentic OCR before extraction.
Why DocuPipe
Built for speed, scale, and accuracy
templates to build, maintain, or update when a new layout shows up
field-level accuracy across formats you've never seen before
from a brand-new layout to structured data, with zero configuration
pages processed across every document type imaginable
Live Demo
See it in action
Try one of our sample documents or upload your own
Sample Document
bill-of-lading.pdf
PDF FILE
export-invoice.png
PNG FILE
purchase-order-1.jpeg
JPEG FILE
purchase-order-2.png
PNG FILE
purchase-order-3.pdf
PDF FILE
Upload your own
Drag a document to the drop zone to get structured results.
Drop document here
Drag a sample from the left or upload your own to see how we standardize it.
Who this is for
Teams that put this on autopilot
Operations teams
Stop rebuilding templates every time a vendor changes a form. Process documents from any source with one schema that never needs per-layout maintenance.
Software builders
Embed extraction that works on documents you've never seen, so your product handles whatever your users upload - no template library to ship or maintain.
Finance & back office
Reconcile invoices, statements, and POs from hundreds of counterparties without a template for each one. Consistent structured output, every format.
Security & compliance
Enterprise-grade security you can trust

SOC 2 Type II
SOC 2 reports are available through our trust center.

ISO 27001
ISO 27001 certification is part of our security program.

GDPR
Paid teams can select Europe as their storage region for new uploads.
Frequently asked questions
Template and forms-based tools learn the position of each field on a specific layout. They work until the layout changes, then they break and need to be retrained or rebuilt. DocuPipe doesn't use positions - its models read the document for meaning, so the same schema extracts correctly across layouts it has never seen, with no per-layout setup.
No. That's the whole point. You define your schema once based on what the fields mean, and it applies to every new layout automatically. A new vendor, a reformatted invoice, or a document type you've never processed all flow through the same schema with no changes.
DocuPipe runs agentic OCR that handles rotated pages, skew, poor scan quality, and handwritten fields before extraction. Variable layout and variable quality are handled together - you don't need a separate pipeline for messy inputs.
Yes. Drop in a batch of mixed documents in different formats and DocuPipe identifies document boundaries, splits them into individual documents, and extracts each according to your schema - no manual sorting.
For typed documents we typically achieve 95%+ field-level accuracy, including on layouts that are new to your account. Every field comes with a confidence score and a citation back to its location in the source, so low-confidence extractions can be routed to human review.
Get up to 20k free credits by signing up