Preventing AI Hallucinations with Visual Review & Provenance
Uri Merhav
Updated Mar 30th, 2026 · 12 min read
Table of Contents
Preventing AI Hallucinations with Visual Review & Provenance
A financial analyst extracts data from quarterly reports. The AI returns a revenue figure of $47.3 million. The analyst enters it into the model. Three weeks later, an auditor discovers the actual figure was $37.4 million. The AI hallucinated a number that looked plausible but was completely wrong.
This scenario plays out daily across enterprises using document AI without proper provenance controls. LLMs confidently produce outputs that have no basis in source documents. Without mechanisms to verify extractions against sources, these hallucinations propagate through systems, corrupt analyses, and eventually surface as audit findings or regulatory violations.
What You Need to Know
The problem: LLMs don't verify their outputs against source documents. They generate statistically plausible values that may be completely fabricated. You can't tell which extractions are real.
Why it happens: Context window degradation, training data contamination, and OCR errors all feed hallucinations. Longer documents are worse. Tables spanning pages are worse.
The fix: Structure-preserving parsing feeds LLMs clean, well-structured input. Confidence scores flag uncertain extractions. Bounding boxes link every value to its exact source location.
Bottom line: You need to see where every number came from. If you can't click a field and see it highlighted in the source document, you're flying blind.
For the broader context on enterprise document AI infrastructure, see the Enterprise Document AI Infrastructure hub article. For how to route uncertain extractions to human review, see The Human-in-the-Loop (HITL) Escalation Protocol.
The Root Cause of LLM Hallucinations in Financial Documents
Hallucinations are not bugs. They are fundamental characteristics of how large language models work. Understanding their causes is essential to mitigating their impact.
Statistical Plausibility vs. Documentary Evidence
LLMs generate outputs that are statistically plausible given their training data. When extracting a revenue figure, the model considers:
- What revenue figures typically look like
- What range is plausible for companies of this type
- What format the output should take
What the model does not reliably do is verify that its output matches specific characters in the source document. The model may produce a number that looks right, sounds right, and fits the pattern, but does not actually appear in the document.
This is especially dangerous because hallucinated values are often plausible. A fabricated revenue of $47.3 million is not obviously wrong for a mid-sized company. Only comparison to the source document reveals the error.
Context Window Degradation
As documents grow longer, extraction quality degrades. Studies demonstrate that LLM performance on simple tasks declines significantly when those tasks are embedded in long contexts. The model loses track of specific details while maintaining general understanding.
For document processing, this means:
- First pages extract more reliably than later pages
- Details mentioned once may be missed or fabricated
- Cross-references between distant sections fail
- Tables spanning many pages produce inconsistent results
The model "knows" approximately what the document contains but cannot reliably pinpoint specific values in specific locations.
Training Data Contamination
LLMs are trained on massive corpora that include financial documents, legal filings, and business records. When extracting from a new document, the model may inadvertently retrieve information from similar documents in its training data rather than the actual source.
This contamination is nearly impossible to detect. The extracted value might be correct for a different company, a different quarter, or a different document entirely. It appears valid but has no basis in the source.
OCR Error Amplification
Before the LLM sees any text, OCR must convert images to characters. OCR errors cascade through extraction:
- A "3" misread as "8" becomes part of a financial figure
- A decimal point missed creates an order of magnitude error
- Two columns merged create nonsensical concatenations
The LLM receiving corrupted OCR output cannot distinguish errors from valid text. It processes what it receives, sometimes "correcting" errors in ways that introduce new fabrications.
Structure-Preserving Parsing: Vision + VLMs
The first defense against hallucinations is ensuring the LLM receives accurate, well-structured input. Structure-preserving parsing accomplishes this through layout-aware processing.
Layout-Aware OCR
Traditional OCR reads text left-to-right, top-to-bottom. This works for simple documents but fails on complex layouts:
- Multi-column formats concatenate unrelated content
- Tables become garbled sequences of numbers
- Headers separate from their associated content
- Reading order becomes ambiguous
Layout-aware OCR understands document structure:
- Identifies columns and reads each separately
- Recognizes tables and preserves cell relationships
- Associates headers with their content blocks
- Determines correct reading order for complex layouts
The result is text that preserves the logical structure of the original document, not just its character content.
Table Structure Preservation
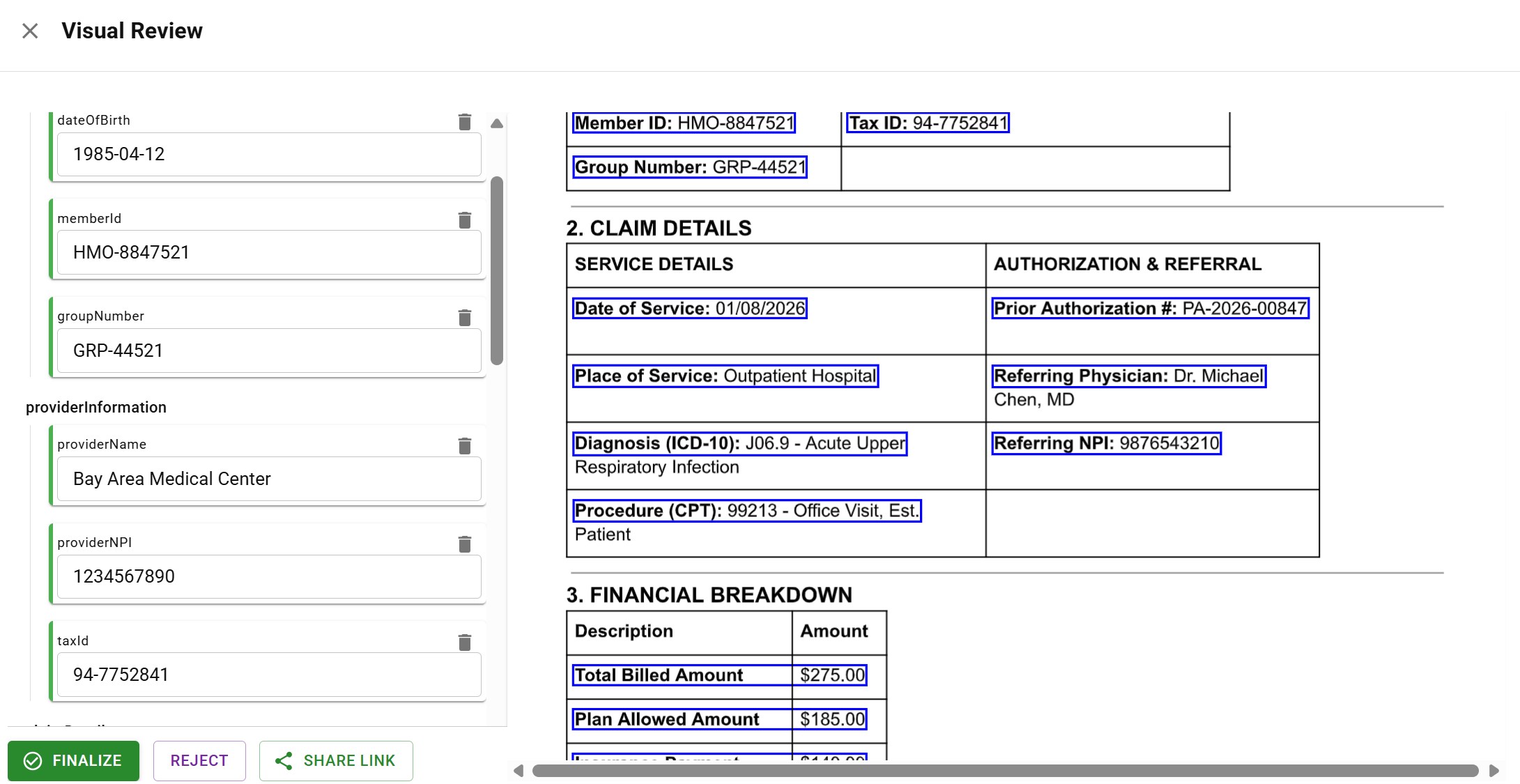 Healthcare claim showing table extraction with bounding boxes
Healthcare claim showing table extraction with bounding boxesTables are particularly vulnerable to hallucinations. A misaligned table produces systematically wrong extractions:
Original table:
Product | Q1 Sales | Q2 Sales
Widget A | 1,234 | 1,456
Widget B | 987 | 1,102
Corrupted extraction:
Product: Widget A
Q1 Sales: 987
Q2 Sales: 1,456
The values exist in the document but are misattributed. This is worse than fabrication because the error is harder to detect.
Structure-preserving parsing maintains cell-level integrity:
- Each cell is extracted with its row and column position
- Header relationships are preserved
- Spanning cells are handled correctly
- Multi-page tables maintain alignment
Multimodal Processing
Some documents cannot be reliably processed through OCR alone. Handwritten content, degraded scans, and complex visual layouts benefit from multimodal processing where the LLM sees page images directly.
Vision-language models can:
- Interpret handwriting that OCR fails to read
- Understand visual relationships (arrows, circles, annotations)
- Process forms where layout conveys meaning
- Handle documents with mixed printed and handwritten content
Multimodal processing is not universally better than OCR. For clean printed documents, OCR provides more reliable text. The optimal approach matches processing mode to document characteristics.
Confidence Thresholds and Visual Review
 DocuPipe visual review interface with bounding boxes
DocuPipe visual review interface with bounding boxesEven with perfect parsing, LLMs can still hallucinate. Confidence scoring provides the second defense layer: mechanisms to detect uncertain extractions and verify them against sources.
Confidence Score Generation
Every extracted field receives a confidence score indicating extraction reliability. Confidence scoring considers:
Text matching:
- Does the extracted value appear verbatim in the document?
- If not, how different is the closest match?
- Are variations explainable (OCR errors, formatting differences)?
Positional consistency:
- Is the value found where similar values typically appear?
- Does its position align with the field type (dates in headers, amounts in tables)?
- Are multiple values found that could match the field?
Cross-field validation:
- Do related fields show consistent values?
- Do computed fields match their components?
- Are there contradictions with other extractions?
Model confidence:
- How certain was the LLM about this extraction?
- Did multiple extraction attempts produce consistent results?
- Were alternative values considered?
Bounding Box Provenance
Every extracted value is linked to exact coordinates in the source document:
{ "field": "total_amount", "value": 47382.50, "confidence": 0.94, "provenance": { "page": 3, "bounding_box": { "x_min": 0.65, "y_min": 0.42, "x_max": 0.78, "y_max": 0.45 }, "source_text": "$47,382.50" } }
These coordinates enable:
- Visual highlighting of extracted values on source documents
- One-click verification by human reviewers
- Audit trails showing exactly where data originated
- Automated comparison between extracted values and source regions
Threshold-Based Routing
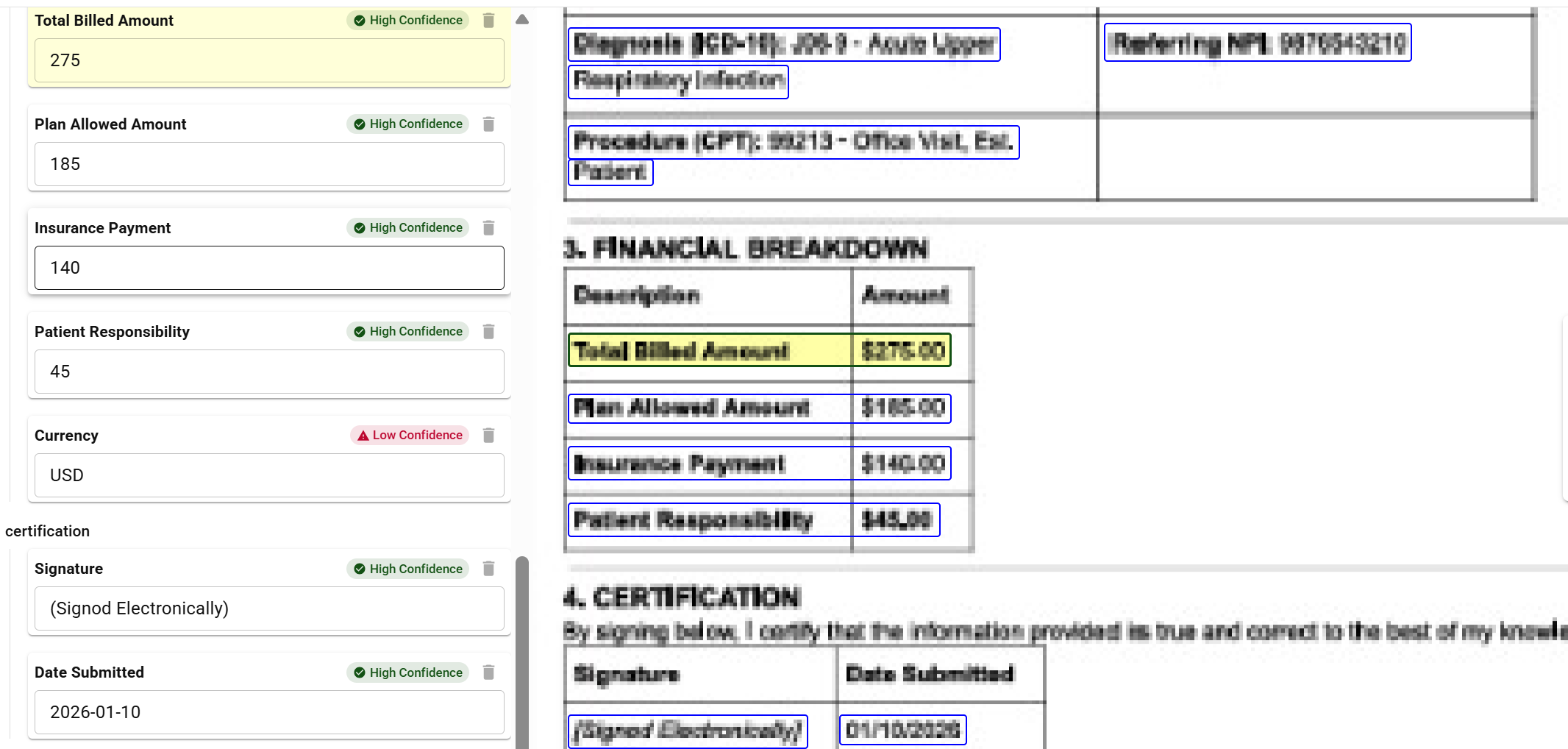 Document extraction showing mixed confidence levels - High and Low indicators for routing decisions
Document extraction showing mixed confidence levels - High and Low indicators for routing decisionsConfidence scores drive workflow routing:
High confidence (~95%+):
- Extraction proceeds without human review
- Data flows directly to downstream systems
- Audit log records automatic approval
Medium confidence (~80-95%):
- Extraction is flagged for potential review
- Data proceeds but is marked for sampling-based verification
- Review catches systematic issues before they propagate
Low confidence (below ~80%):
- Extraction is queued for human review
- Data does not proceed until verified
- Reviewer sees extracted value alongside source highlighting
Visual Review Interface
Human review is only effective if it is fast. The visual review interface enables rapid verification:
Side-by-side display:
- Extracted data appears next to source document
- Relevant regions are highlighted automatically
- Reviewer can compare without manual searching
One-click verification:
- Accept extraction if correct
- Reject if incorrect
- Correct value directly in the interface
Correction capture:
- When values are corrected, both original and corrected values are recorded
- Correct bounding boxes are updated
- Corrections feed model improvement
Batch review:
- Multiple documents reviewed in sequence
- Consistent interface across document types
- Review multiple fields within the same document efficiently
Audit Trail Generation
Every extraction produces a complete audit trail:
Processing record:
- Document identifier and source file hash
- Timestamp of processing
- Model versions used
- Processing parameters applied
Extraction record:
- All extracted fields with values
- Confidence scores for each field
- Bounding box coordinates
- Source text for each extraction
Review record:
- Whether human review occurred
- Reviewer identifier
- Original and corrected values if changed
- Timestamp of review
Downstream record:
- Where data was sent
- Confirmation of receipt
- Any transformation applied
This audit trail enables:
- Regulatory compliance demonstrations
- Root cause analysis when errors are discovered
- Performance monitoring over time
- Evidence for legal proceedings
Implementation Patterns
Deploying hallucination prevention requires architectural decisions about thresholds, workflows, and continuous improvement.
Threshold Calibration
Confidence thresholds are not universal. They must be calibrated for:
Document type:
- Clean printed invoices can use higher thresholds
- Handwritten forms require lower thresholds
- Complex multi-page documents need intermediate settings
Field criticality:
- Financial amounts may require higher confidence
- Reference numbers can tolerate more uncertainty
- Free-text fields have inherent variability
Error cost:
- High-cost errors justify more human review
- Low-cost errors can tolerate higher automation
- Regulatory requirements may mandate specific thresholds
Calibration is an ongoing process. Initial thresholds are estimates. Production performance data refines them continuously.
Feedback Loop Integration
Human corrections improve extraction quality over time:
Correction analysis:
- Which fields are corrected most frequently?
- What types of errors predominate?
- Are there patterns by document type or source?
Model fine-tuning:
- Accumulated corrections become training examples
- Models are retrained on corrected data
- Performance is measured before and after retraining
Prompt refinement:
- Error patterns suggest prompt improvements
- Field descriptions are refined based on failures
- Examples are added to address common mistakes
Threshold adjustment:
- Fields with high correction rates get lower confidence
- Fields with few corrections can tolerate higher automation
- Adjustments are gradual and monitored
Quality Monitoring
Ongoing quality monitoring detects degradation before it causes problems:
Sampling-based verification:
- Random sample of high-confidence extractions reviewed
- Compares human judgment to automated confidence
- Detects model drift or data shift
Outlier detection:
- Unusual values flagged for review
- Statistical anomalies investigated
- New document types identified automatically
Trend analysis:
- Confidence distributions tracked over time
- Correction rates monitored by period
- Alerts when metrics deviate from baselines
Key Takeaways
- LLMs hallucinate because they generate plausible outputs, not verified ones - the $47.3M looks right even when the document says $37.4M
- Longer documents are worse - context window degradation means page 50 extracts less reliably than page 1
- Structure-preserving parsing is the first defense - feed LLMs clean, well-structured input instead of raw images
- Confidence scores tell you what to trust - high confidence proceeds automatically, low confidence gets human review
- Bounding boxes are non-negotiable - if you can't click a field and see it highlighted in the source, you're guessing
See exactly where your data comes from.
LLMs generate statistically plausible outputs based on training data patterns, not by verifying against source documents. They may produce values that look right for companies of a certain type without confirming those values actually appear in the document. Context window degradation, training data contamination, and OCR error amplification compound the problem.
Every extracted value is linked to exact coordinates (x_min, y_min, x_max, y_max) in the source document. This enables visual highlighting of extracted values, one-click verification by human reviewers, audit trails showing exactly where data originated, and automated comparison between extracted values and source regions.
Each extraction receives a confidence score based on text matching, positional consistency, cross-field validation, and model certainty. High confidence (~95%+) proceeds automatically. Medium confidence (~80-95%) is flagged for potential review. Low confidence (below ~80%) requires human verification before proceeding.
Recommended Articles
Related Documents