The Enterprise Document AI Infrastructure: Built for Zero-Trust & Legacy Scale
Uri Merhav
Updated Mar 31st, 2026 · 18 min read
Table of Contents
The Enterprise Document AI Infrastructure: Built for Zero-Trust & Legacy Scale
Every enterprise AI deployment starts with the same question: can we trust this system with our most sensitive documents?
For government agencies processing classified intelligence, healthcare systems handling protected health information, and financial institutions managing audit-critical records, the answer is almost always no. Not because the AI models are inadequate, but because the infrastructure surrounding them was designed for demos, not deployments.
The document AI market is flooded with thin API wrappers that promise extraction in minutes. Upload a PDF, get JSON back, ship it to production. This pitch works for startups processing simple, formatted, typed invoices. It fails catastrophically for any organization that faces real world documents, regulatory audits, handles classified data, or depends on deterministic outputs for downstream systems.
This article outlines the infrastructure requirements for enterprise document AI. We will dive into why most solutions fail security assessments, how to architect pre-extraction pipelines for massive document volumes, the five layers of zero-trust document processing, and the deployment realities of IL5, IL6, and true air-gapped environments.
The Abstraction Trap: Why SaaS Wrappers Fail the Enterprise
The typical document AI vendor offers a simple value proposition: send us your documents via API, and we will return structured data. Behind that API sits a shared infrastructure processing documents from hundreds of customers simultaneously.
This model has three fatal flaws for enterprise deployment.
Shared Telemetry Exposes Data Boundaries
Multi-tenant SaaS platforms aggregate logging, metrics, and model telemetry across all customers. Even when document contents are encrypted, metadata leaks through shared observability pipelines. Which document types are being processed? What schemas are being applied? How long does extraction take for specific formats?
Security auditors at federal agencies and Fortune 500 companies routinely fail vendors who cannot demonstrate complete telemetry isolation. The question is not whether your data is encrypted. The question is whether your processing patterns are visible to other tenants or the vendor's operations team.
Model Updates Break Validation
When a SaaS vendor updates their extraction models, every customer receives the change simultaneously. For regulated industries, this creates an impossible compliance burden.
Consider a pharmaceutical company using document AI to extract data from clinical trial reports. Under 21 CFR Part 11, any system producing electronic records must be validated. When the vendor pushes a model update, the customer's validation is invalidated. They must re-test, re-document, and re-certify before continuing production use.
Enterprise deployments require model version pinning, controlled rollouts, and the ability to roll back to previously validated versions. Most SaaS wrappers offer none of these capabilities.
Opaque Data Flows Fail Audit
Where does your document go after you send it to the API? Which regions process it? How long is it retained? Who can access it during processing?
These questions have precise answers in compliant systems. In most document AI platforms, the answers are buried in terms of service that reserve broad rights for the vendor. Government procurement officers and healthcare compliance teams reject vendors who cannot provide architectural diagrams showing exact data flows, storage locations, and access controls.
The abstraction that makes SaaS convenient is the same abstraction that makes it unauditable.
Processing Large Documents: Pre-Extraction Orchestration
 Pre-Extraction Orchestration Pipeline showing document intake through layout analysis, semantic chunking, classification, and specialist routing
Pre-Extraction Orchestration Pipeline showing document intake through layout analysis, semantic chunking, classification, and specialist routingEnterprise document processing rarely involves clean, single-page inputs. The reality is far messier.
A typical government records request might return a 1,200-page PDF containing contracts, correspondence, spreadsheets, and handwritten notes concatenated into a single file. A healthcare system might receive faxed documents where multiple patient records are scanned together. A legal discovery process might produce terabytes of mixed-format archives.
Standard document AI fails immediately when confronted with these massive files. AI context limits overflow. Context is lost. Extraction quality collapses.
The Shift from ETL to ELT
Traditional document processing follows an ETL pattern: Extract structure during ingestion, Transform it into normalized formats, then Load it into target systems. This approach assumes you know the document structure before processing begins.
For enterprise document AI, the ELT pattern is superior: Load raw documents first, preserve all original information, then apply structure at query time through Schema-on-Read.
Why does this matter? Because extraction requirements change. The schema you need today is not the schema you will need after the next audit finding. By preserving raw documents and applying structure dynamically, you can re-extract historical documents with new schemas without re-ingesting the originals.
This is not a theoretical advantage. Organizations that adopted ETL patterns for document AI are now stuck. They extracted fields A, B, and C five years ago. Now regulators want field D, which existed in the original documents but was discarded during transformation. ELT architectures avoid this trap entirely.
Semantic Chunking and Layout Graphs
Before any extraction can occur, massive documents must be decomposed into processable units. This decomposition cannot be arbitrary.
Page-based splitting fails when tables span multiple pages. Fixed-token chunking fails when it bisects paragraphs or separates headers from their content. Simple approaches produce garbage that even the best extraction models cannot salvage.
Intelligent pre-extraction requires building a layout graph for each document. This graph represents the structural relationships between elements: which paragraphs belong to which sections, which tables span which pages, which headers apply to which content blocks.
With a layout graph in place, semantic chunking becomes possible. The system identifies natural document boundaries and splits along them. A 1,200-page file becomes 47 discrete sub-documents, each internally coherent and ready for specialized processing.
Routing to Specialist Models
Not all document content should be processed by the same model. A page containing dense tabular data requires different handling than a page of narrative text. Handwritten annotations demand different capabilities than printed forms.
Layout-aware orchestration examines each chunk and routes it to the appropriate specialist. Tables go to models optimized for cell-level extraction. Handwritten regions go to models trained on cursive recognition. Standard text goes to high-throughput general extractors.
This routing happens automatically based on the layout graph. The orchestration layer examines each chunk's characteristics and selects the optimal processing path. No human configuration is required for each document.
Operational Scale and Reliability
Enterprise document processing demands infrastructure that handles volume spikes and maintains availability:
Auto-scaling infrastructure:
- Automatic scaling based on queue depth and processing load
- Burst handling for month-end, quarter-end, and audit periods
- No manual intervention required for capacity changes
Priority processing:
- Urgent documents can be prioritized in the processing queue
- Critical workflows proceed ahead of routine batch processing
- SLA-based routing for time-sensitive extractions
Disaster recovery:
- Cross-region redundancy for high availability
- Automatic failover if primary region experiences issues
- Data replication ensures no document loss during incidents
The DocuPipe Trust Stack: Five Layers of Zero-Trust Document AI
Zero-trust architecture assumes that no component of a system can be implicitly trusted. Every request must be authenticated. Every action must be authorized. Every data flow must be auditable.
For document AI, zero-trust extends beyond network security to encompass the entire processing pipeline. The DocuPipe Trust Stack defines five layers that must each be independently secured.
Layer 1: Data Protection
Data protection encompasses encryption, isolation, and residency controls.
Encryption requirements:
- Documents encrypted at rest and in transit
- Encryption using industry-standard protocols
Isolation requirements:
- For VPC and on-premise deployments: dedicated compute within customer environment
- For cloud SaaS: logical tenant isolation with access controls
- Network segmentation enforcing traffic controls
Residency requirements:
- Processing restricted to customer-specified geographic regions
- Data sovereignty compliance for GDPR, Canadian PIPEDA, and sector-specific mandates
- Audit logs demonstrating no cross-border data transfers
Layer 2: Certification
Certifications provide third-party validation of security controls. Enterprise procurement requires specific certifications depending on the industry and data classification.
Baseline certifications:
- SOC 2 Type II (required for any enterprise SaaS)
- ISO 27001 (required for international deployments)
- HIPAA Business Associate Agreement capability (required for healthcare)
Certifications are not checkboxes. They represent ongoing operational commitments that must be maintained through continuous compliance monitoring.
Layer 3: Provenance
Every piece of extracted data must be traceable to its source. This is not optional for regulated industries.
Field-level provenance:
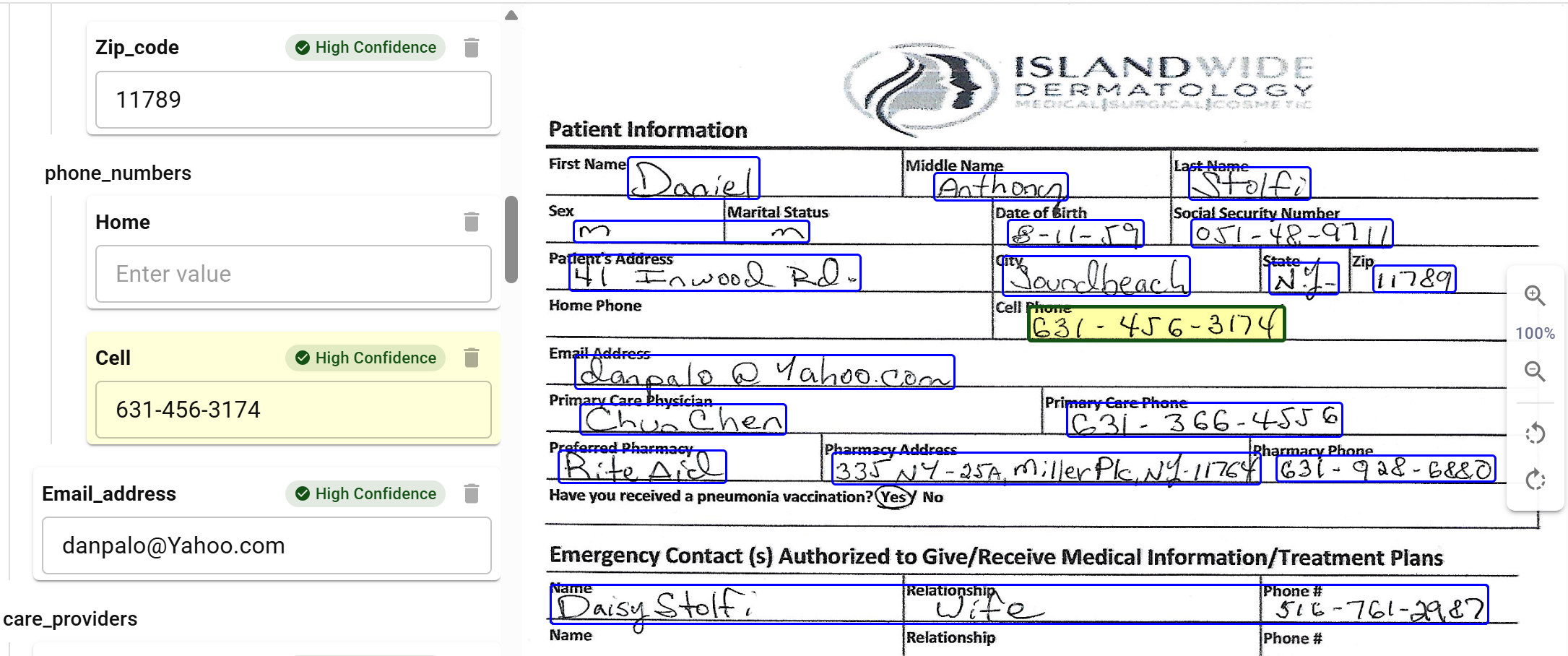 Visual review showing extracted fields with bounding boxes and confidence
Visual review showing extracted fields with bounding boxes and confidence- Each extracted value linked to exact bounding-box coordinates (x_min, y_min, x_max, y_max)
- Page numbers and document identifiers preserved through the extraction pipeline
- Visual highlighting enabling human reviewers to verify extractions against source documents
Processing provenance:
- Complete audit trail of which models processed each document
- Model version identifiers for every extraction
- Timestamps for each processing step
- User identifiers for any human review or correction
Change provenance:
- Full history of any corrections or overrides
- Before and after states preserved for audit
- Reason codes for changes when required by workflow
Provenance is what transforms document AI from a black box into an auditable system. When a regulator asks "where did this number come from?", you must be able to show them the exact pixel region in the source document and the complete chain of processing that produced the extracted value.
Layer 4: Model Governance
AI models are not static software. They drift, degrade, and occasionally hallucinate. Enterprise deployments require governance controls that traditional software lacks.
Version control:
- Model version selection allowing customers to pin to specific versions
- Rollback capabilities to previous model versions
- Change logs documenting modifications between versions
Performance monitoring:
- Accuracy measurement against validation samples
- Quality tracking across document types
- Human review feedback integration
Model governance is where many document AI deployments fail. The initial deployment works well, but over time, document populations shift, edge cases accumulate, and quality degrades without anyone noticing until a major error surfaces.
Layer 5: Access Control
Access control for document AI extends beyond user authentication to encompass the entire processing pipeline.
User access:
- Role-based access control (RBAC) with principle of least privilege
- Multi-factor authentication for all administrative access
- Session management with automatic timeouts
- Audit logging of all user actions
API access:
- API keys scoped to specific operations and document types
- Rate limiting to prevent abuse
- IP allowlisting for production integrations
- Separate credentials for development, staging, and production
System access:
- Service accounts with minimal required permissions
- Secrets management using vault systems
- Credential rotation on defined schedules
- Network policies restricting inter-service communication
The goal of access control is to ensure that even if one component is compromised, the blast radius is contained. No single credential should grant access to all customer data or all system capabilities.
Deterministic Outputs from Probabilistic Models
Large language models are probabilistic. Given the same input, they may produce slightly different outputs. For many applications, this variability is acceptable. For enterprise document processing, it is not.
When extracted data feeds into an ERP system, the schema must match exactly. When extracted values populate a regulatory filing, the format must be precise. When extracted records enter a database, the types must be correct.
The solution is Schema-on-Read: applying rigid structure to LLM outputs at extraction time rather than hoping the model produces the right format.
JSON Schema as Contract
Every extraction operation begins with a schema definition. This schema specifies exactly what fields should be extracted, what types they should have, and what constraints they must satisfy.
{ "type": "object", "properties": { "invoice_date": { "type": "string", "format": "date", "description": "Invoice date in ISO 8601 format (YYYY-MM-DD)" }, "total_amount": { "type": "number", "minimum": 0, "description": "Total invoice amount in USD" }, "line_items": { "type": "array", "items": { "type": "object", "properties": { "description": { "type": "string" }, "quantity": { "type": "integer", "minimum": 1 }, "unit_price": { "type": "number", "minimum": 0 } }, "required": ["description", "quantity", "unit_price"] } } }, "required": ["invoice_date", "total_amount"] }
This schema guides extraction. The model extracts the fields you specify in the formats you describe.
Downstream Validation
Schema-driven extraction produces consistent output structure, but enterprise integrations often require additional validation before data reaches target systems. Your integration layer should implement:
Validation checks:
- Type verification (confirm strings, numbers, arrays match expectations)
- Format validation (ISO 8601 dates, currency codes, email addresses)
- Required field checks (verify critical fields are present)
- Business rule validation (amounts within expected ranges, dates in sequence)
Tools like Pydantic, JSON Schema validators, or database constraints handle this validation. When validation fails, route documents to human review or correction queues.
The key principle: validate before loading to downstream systems. DocuPipe provides structured extraction; you control validation rules specific to your business requirements.
Consistent Field Ordering
Beyond type validation, enterprise integrations often require consistent field ordering. Legacy systems may parse JSON positionally rather than by key. Database bulk loaders may expect columns in specific sequences.
Schema-driven extraction ensures that output fields always appear in the order defined by the schema. This ordering is preserved across all documents, all batches, and all model versions. Downstream systems can rely on positional consistency without parsing overhead.
The 2026 Enterprise Deployment Mandate
The deployment landscape for enterprise document AI is fragmenting. Organizations are no longer asking whether to use AI for document processing. They are asking where that processing can occur and under what constraints.
VPC Deployment
For many enterprises, the minimum acceptable deployment is within their own Virtual Private Cloud. VPC deployment provides network isolation, private endpoints, and integration with existing security infrastructure.
VPC requirements:
- No public IP addresses on processing infrastructure
- Private Link or VPC peering for API access
- Customer-managed encryption keys integrated with cloud KMS
- Logging to customer-owned SIEM systems
- No egress to vendor systems for telemetry or updates
VPC deployment is sufficient for many commercial use cases and some government workloads at lower classification levels. It provides meaningful isolation while still leveraging cloud infrastructure for scalability and maintenance.
IL5 and IL6 Authorization
Department of Defense workloads require Impact Level authorization. IL5 covers Controlled Unclassified Information (CUI) in dedicated cloud environments. IL6 covers classified information up to SECRET in government-owned facilities.
IL5 requirements:
- Deployment in FedRAMP High authorized cloud regions
- Processing by U.S. persons only
- Physical and logical separation from commercial workloads
- Continuous monitoring with government-accessible dashboards
- Incident response procedures meeting DoD timelines
IL6 requirements:
- Deployment in government-owned data centers or approved facilities
- Air-gapped networks with no external connectivity
- Cleared personnel for all operations and maintenance
- Hardware verification and supply chain documentation
- Cross-domain solutions for any data transfers
The path to IL6 authorization is measured in years and millions of dollars. Organizations requiring IL6 document AI must plan accordingly or accept that some documents cannot be processed by external systems.
True Air-Gapped Deployment
Air-gapping is frequently misunderstood. A system is not air-gapped simply because it lacks a public IP address. True air-gapping requires physical network isolation with no routable path to external systems.
Air-gap requirements:
- Physically separate network infrastructure
- Updates delivered via removable media through cross-domain procedures
- No wireless capabilities on processing systems
- Tempest certification for facilities processing classified data
- Physical access controls with multi-person integrity
For document AI, air-gapped deployment means the entire processing stack must run within the isolated environment. This includes OCR models, extraction models, validation logic, and human review interfaces. Nothing can depend on external API calls or cloud services.
DocuPipe supports true air-gapped deployment through containerized delivery of the complete processing stack. All models, all logic, and all interfaces are packaged for installation in disconnected environments. Updates are delivered as versioned releases that can be transferred through approved cross-domain channels.
The Deployment Decision Framework
Organizations must evaluate their document portfolios against deployment options. Not all documents require the same protection level.
Cloud SaaS may be appropriate for:
- Marketing collateral
- Public filings and disclosures
- Non-sensitive operational documents
VPC deployment may be appropriate for:
- Customer information and PII
- Financial records below regulatory thresholds
- Internal communications and policies
On-premises or air-gapped may be required for:
- Classified or controlled information
- Documents subject to data sovereignty requirements
- Records where any external processing creates regulatory risk
The goal is not to apply maximum security to every document. The goal is to match security controls to actual risk while maintaining operational efficiency for lower-risk workloads.
Conclusion: Infrastructure First
Enterprise document AI is not a model problem. It is an infrastructure problem.
The models exist. Extraction accuracy has reached levels that exceed human performance on many document types. The challenge is deploying those models in environments that meet enterprise security, compliance, and operational requirements.
Organizations evaluating document AI vendors should invert the typical evaluation process. Instead of starting with accuracy benchmarks and pricing, start with infrastructure questions:
- Where will our documents be processed?
- Who will have access to them during processing?
- How will we audit what happened to each document?
- Can we control model versions and rollback if needed?
- Does this deployment meet our regulatory obligations?
Vendors who cannot answer these questions precisely are not ready for enterprise deployment, regardless of how impressive their demos appear.
The DocuPipe Trust Stack provides a framework for evaluating document AI infrastructure. Each layer must be addressed: data protection, certification, provenance, model governance, and access control. Gaps in any layer create risks that will surface during audits, incidents, or regulatory examinations.
Build the infrastructure first. The extraction quality will follow.
The DocuPipe Trust Stack is a five-layer security framework for enterprise document AI: Data Protection (encryption, isolation, residency), Certification (SOC 2 Type II, ISO 27001, HIPAA), Provenance (bounding-box coordinates, audit trails), Model Governance (version control, quality monitoring), and Access Control (RBAC, API scoping, secrets management). Each layer must be independently secured for zero-trust document processing.
Yes. DocuPipe supports air-gapped deployment through containerized delivery of the complete processing stack. All models, validation logic, and interfaces are packaged for installation within customer VPC environments. The on-premise deployment runs entirely within the customer's infrastructure with no external dependencies.
Traditional ETL extracts specific fields during ingestion and discards the rest. Schema-on-Read preserves raw documents and applies structure at query time. This means you can extract new fields from historical documents without re-ingesting originals. Critical when audit requirements change or regulators request previously unextracted information.
DocuPipe supports cloud SaaS (managed infrastructure), dedicated cloud (single-tenant), VPC deployment (customer-controlled environment with private endpoints), on-premise deployment (complete infrastructure ownership), and air-gapped deployment (true network isolation for classified workloads). Each model provides identical extraction capabilities with different security controls.
Recommended Articles
Related Documents