11 min read
DocuPipe vs Textract: Which is best for your team? [2026]
Uri Merhav
Published January 15, 2026
Updated February 24, 2026

Looking for the best Amazon Textract alternative? DocuPipe vs Textract comes down to this: DocuPipe gives you structured data in one API call, with visual review built in. AWS Textract is solid OCR, but before you extract your first PDF, you're configuring S3 buckets, IAM roles, Lambda functions, and SNS notifications. And when you finally get data back from Textract, it's raw messy text with random box coordinates - not structured fields. If you're okay with parsing raw OCR output yourself, Textract works. But if you want clean JSON organized by your schema, DocuPipe is what you need.
Table of Contents
- DocuPipe vs Textract at a glance
- Amazon Textract alternative: DocuPipe is one API call vs AWS infrastructure
- Structured data vs bounding boxes: the fundamental Textract vs DocuPipe difference
- Amazon Textract vs DocuPipe: simple webhooks vs complex AWS infrastructure
- Document extraction accuracy: Textract Adapters vs DocuPipe corrections
- Human-in-the-loop review: Amazon A2I vs DocuPipe's built-in interface
- What Textract users actually say
- On-premise document extraction: why teams choose DocuPipe over Textract
- Amazon Textract pricing vs DocuPipe: per-feature vs all-inclusive
- Which should you choose?
- FAQ
DocuPipe vs Textract at a glance
| DocuPipe | Textract | |
|---|---|---|
| Best for | Teams shipping product, not infrastructure | Teams with a suite of AWS engineers |
| Time to first extraction | Minutes (API key + one endpoint) | Days to weeks (S3, IAM, Lambda, SNS) |
| PDF processing | Simple async with webhooks. Any doc size. | Complex async (S3 + SNS + Lambda) |
| Output format | JSON with your fields, ready to use | Raw text + bounding boxes |
| Table extraction | Structured rows/columns in JSON | Raw arrays you parse yourself |
| Human review | Built-in UI with source highlighting | Build it yourself (or wire up A2I) |
| Deployment | Cloud or on-premise | AWS cloud only |
| Compliance | SOC 2 Type II, HIPAA, ISO 27001 | HIPAA eligible (you secure the pipeline) |
| Pricing | Free tier, then tiered credit system. No infrastructure cost. | $2-$120 per 1K pages + S3 + Lambda + engineering costs |
Ready to see the difference?
Get up to 20,000 free credits with an eligible work email. No credit card required.
Amazon Textract alternative: DocuPipe is one API call vs AWS infrastructure
If you're evaluating Amazon Textract alternatives, setup complexity is a difference you'll quickly notice. DocuPipe keeps document extraction simple. Get an API key, send a document to our document extraction API, get structured data back. Need human review? It's built in with source highlighting. You're extracting documents in minutes. Simple as that.
While it is true that AWS Textract looks simple in the docs, production use requires an entire AWS infrastructure. You need an S3 bucket because Amazon Textract won't take PDFs directly as byte arrays. Then IAM roles so Textract can read that bucket. For multi-page PDFs, you'll then need async processing with polling or SNS notifications wired to Lambda.
For teams building a product, DocuPipe's intelligent document processing API lets you focus on your application instead of complex AWS plumbing. For teams that already have AWS expertise and a dedicated group of people that can handle the workload of a complex pipeline, Amazon Textract can provide some of that flexibility.
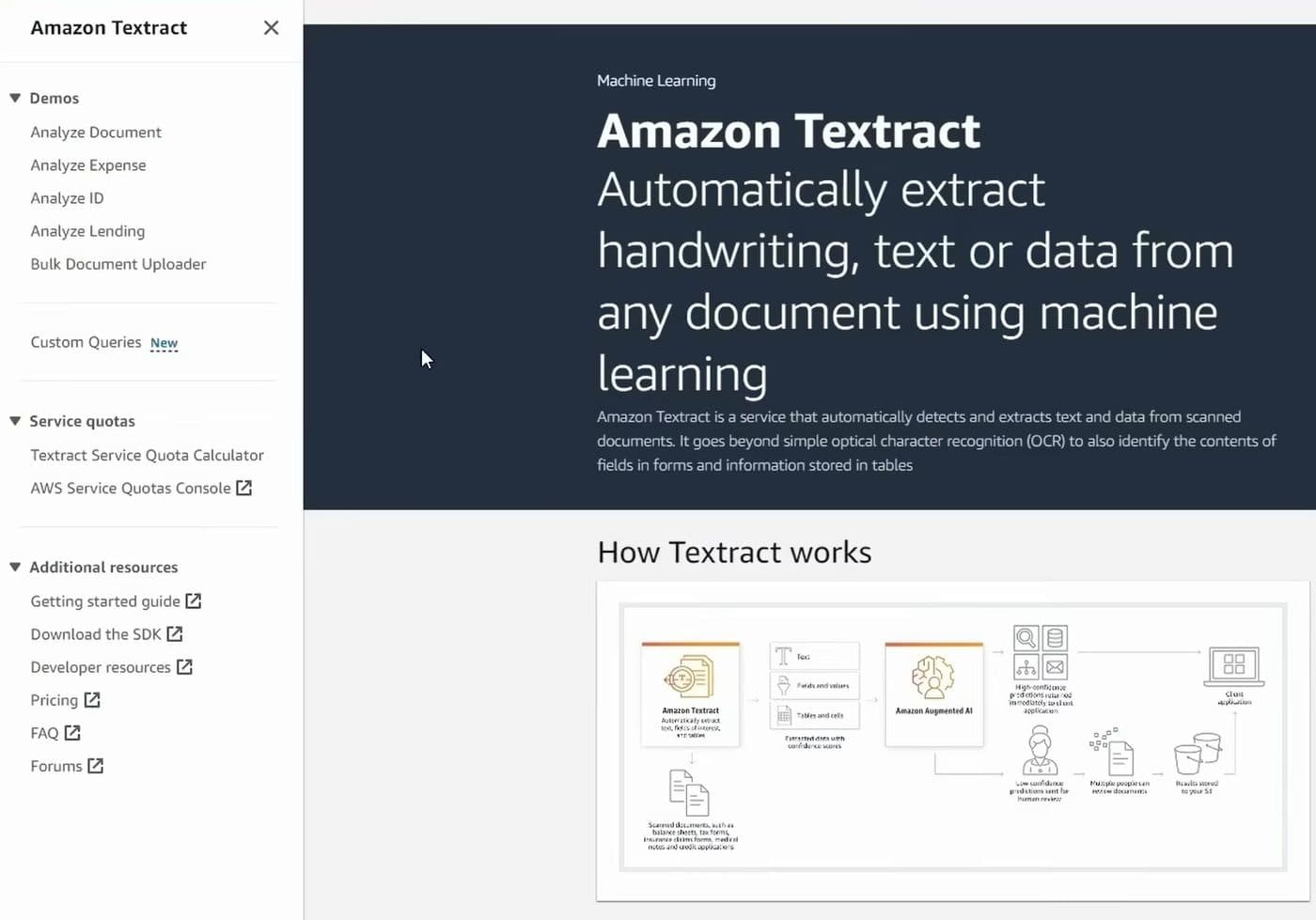
Structured data vs bounding boxes: the fundamental Textract vs DocuPipe difference
A core difference between DocuPipe and Amazon Textract is the output quality. Textract offers decent results for forms and structured documents with good handwriting recognition for predictable locations. But independent benchmarks show Textract can be up to 20% less accurate on complex, real-world documents compared to modern vision-first approaches. It lacks the advanced document understanding needed for complex layouts or unstructured content. Performance degrades significantly for edge cases - mixed printed/handwritten text, degraded quality scans, and domain-specific terminology all cause problems.
Amazon Textract returns raw OCR with artifacts. Table extraction is particularly problematic - merged cells split incorrectly, headers get misaligned, row relationships break on complex layouts. There's no document splitting (upload a PDF with 5 invoices and Textract treats it as one document), no workflow orchestration, no schema versioning, and no evaluation frameworks for regression testing. It's basic extraction without the tooling you need for production.
This matters because most teams don't want to build an entire document understanding system - they want extracted usable data. With Textract, you'll spend weeks to months writing code to interpret the boxes, fix table artifacts, and map everything to your data model. With DocuPipe, you define your schema once and get structured, validated data back immediately. No post-processing. No artifact cleanup. Just the data you need.
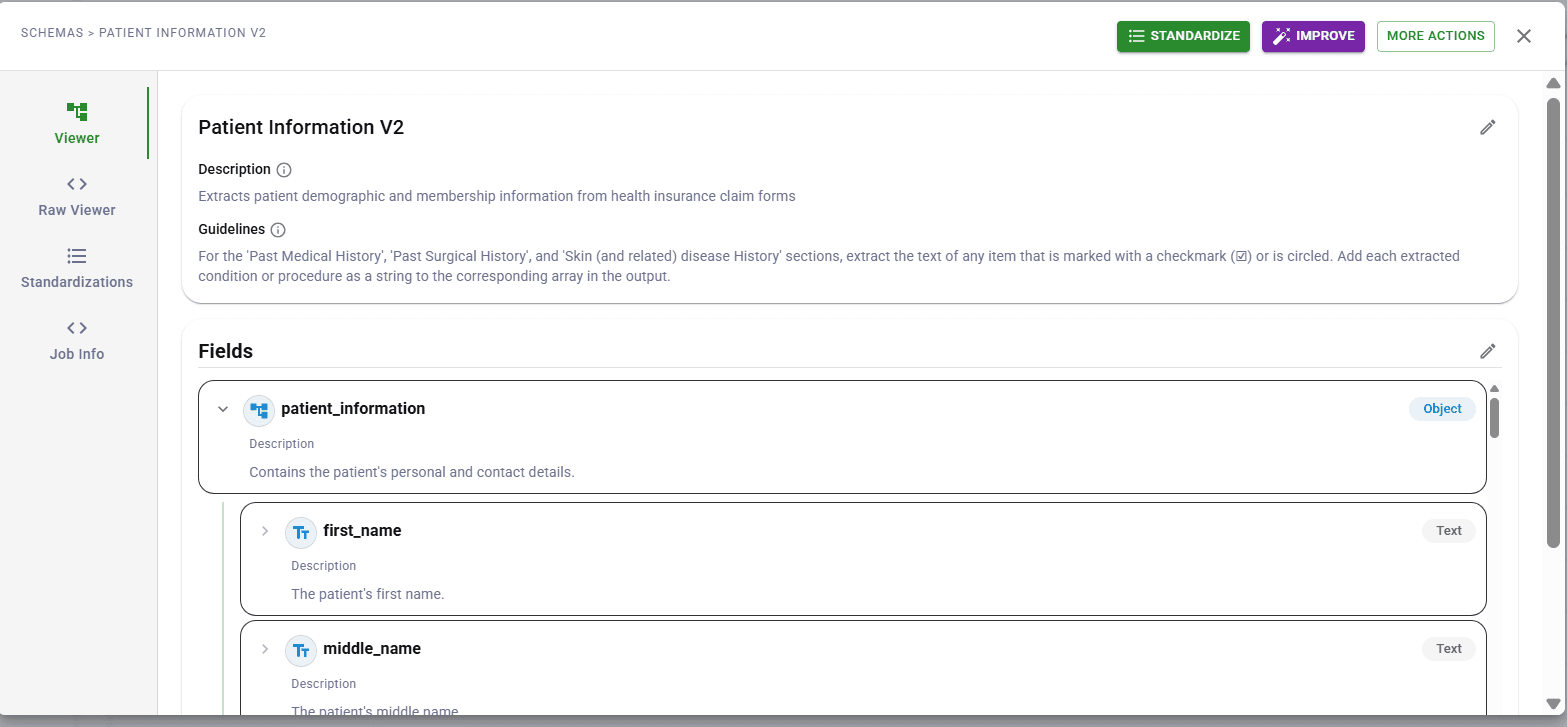
Amazon Textract vs DocuPipe: simple webhooks vs complex AWS infrastructure
Integration simplicity is a key differentiator in the Textract vs DocuPipe comparison. DocuPipe handles async processing with built-in Svix webhooks - submit a document and get notified when it's ready. No infrastructure to build. Large documents are supported out of the box.
Amazon Textract requires you to build your own async infrastructure. That means S3 buckets for document storage, SNS topics for notifications, Lambda functions for processing, and IAM roles to wire it all together. For high-volume document extraction, this adds both complexity and maintenance overhead.
For teams that want to focus on their product instead of AWS plumbing, DocuPipe's simple webhook-based API gets you to production faster. For teams already deep in AWS with dedicated DevOps resources, Textract's infrastructure can work - but you're building it yourself.
Document extraction accuracy: Textract Adapters vs DocuPipe corrections
When comparing Amazon Textract vs DocuPipe for document extraction accuracy, the improvement model differs significantly. DocuPipe's review interface is built in. When the system is unsure of something, a human can verify and correct it right there, with the source document highlighted next to the extracted data. This way, your team can fix errors as they come up, no ML expertise required.
On the other hand, AWS Textract offers fine-tuning through complex Adapters. You provide 5 to 2,500 labeled documents, train a custom adapter, and pay $25 per 1,000 pages to use it. For large teams with extensive ML expertise and labeled training data, this gives you control over the model.
DocuPipe is designed for teams that want maximal document extraction accuracy through high quality, fast technology. Amazon Textract is designed for teams that can invest time and money in training data upfront. DocuPipe is built for every document type, while Textract is designed to be trained for specific preset formats.
See it in action
Up to 20,000 free credits with an eligible work email. No credit card required.
Human-in-the-loop review: Amazon A2I vs DocuPipe's built-in interface
For many considering different document verification workflows, the Textract vs DocuPipe comparison comes down to build vs buy. DocuPipe ships with visual review built in. Click any extracted field and see exactly where it came from on the source document, highlighted in yellow. Your ops team can start reviewing documents today with zero technical background.
Amazon Textract returns JSON that can be built to come with bounding boxes. For human review, AWS offers Amazon Augmented AI (A2I). But A2I requires Cognito user pools for authentication, custom HTML task templates for the review UI, and Lambda functions to translate Textract's output. For teams already deep in AWS, this can be familiar territory.
For regulated industries like healthcare, insurance, or finance, audit trails are non-negotiable. DocuPipe's built-in verification layer handles this out of the box. With AWS Textract, you'll need to build that compliance layer yourself on top of A2I - adding weeks to months of integration work to your timeline.

What Textract users actually say
Textract is solid OCR - until it isn't. A Gartner reviewer puts it plainly: 'Gets the job done but it's not always precise with complex layouts or industry-specific terms. Requires extra cleanup and custom logic to make the output usable.' Independent testing puts overall accuracy at around 90% - good for simple forms, problematic for production pipelines where every field matters.
The technical limitations compound: you need to build your own async infrastructure with S3, SNS, and Lambda. Rate limits drop to 1 transaction per second outside major AWS regions. And before any of that, you're configuring IAM roles and bucket policies.
DocuPipe is one simple API with built-in webhooks. No AWS infrastructure required. A G2 reviewer called our schema builder 'best in class' - and they'd tried three other platforms first. DocuPipe holds a 4.9/5 on G2.
On-premise document extraction: why teams choose DocuPipe over Textract
Data residency is a common reason teams look for Amazon Textract alternatives. DocuPipe offers on-premise deployment. This is helpful because it means that the entire intelligent document processing pipeline can run inside your infrastructure. Sensitive documents never leave your network. For highly regulated industries such as healthcare systems, government agencies, and financial institutions with strict data residency requirements, this is often the deciding factor.
AWS Textract runs on AWS and requires S3 for document storage. Amazon offers compliance certifications, but you're responsible for securing the entire pipeline - IAM roles, bucket policies, encryption, access logging. For organizations already deep in AWS with dedicated cloud security teams, this is manageable overhead.
But if you need self-hosted document extraction where documents never leave your infrastructure, DocuPipe's enterprise deployment is the only path. On-premise deployment isn't possible with Textract - your documents must go to AWS.
Amazon Textract pricing vs DocuPipe: per-feature vs all-inclusive
Pricing is often the deciding factor when evaluating AWS Textract alternatives. DocuPipe uses a tiered credit system for document extraction. You purchase a set amount of credits per month, with overage available if you need it. The key difference? Credits work for everything - extraction, review, standardization. Want to review a document? Just use some credits. No separate fees for different features.
AWS Textract pricing works differently - you pay per feature, and the costs stack up fast. Basic OCR starts at $2.10 per 1,000 pages. Need forms extraction? That jumps to $70 per 1,000 pages. Add tables and you're at $91 per 1,000 pages. Want queries too? Now it's $96 per 1,000 pages. And if you need custom adapters for your specific documents, add another $25 per 1,000 pages on top - pushing you past $120 per 1,000 pages. Then factor in S3 storage, Lambda execution, CloudWatch logs, and SNS notifications. The total cost of ownership often surprises teams who only looked at the initial per-page pricing.
With DocuPipe, budgeting is straightforward - a simple credit system that covers everything. With Amazon Textract, you're managing multiple line items and infrastructure costs. If predictable pricing matters to your team, this is important to consider.
Which should you choose?
Choose DocuPipe if...
You want structured data organized by your schema
You want to ship a document extraction feature in days, not weeks
You don't want to build entire parsing logic to interpret OCR output
You want simple API integration with built-in webhooks
You want human review with source highlighting built in
You prefer predictable, all-inclusive pricing without infrastructure costs
You need on-premise deployment for data residency requirements
Choose Textract if...
You only need raw OCR text
You have a dedicated team of AWS engineers to build custom parsing systems
You're already deep in the AWS ecosystem and want everything in one place
You need Textract's Adapters for custom model fine-tuning with labeled data
Building your own S3/SNS/Lambda infrastructure is acceptable
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
Amazon Textract returns raw OCR text with bounding box coordinates - pixel positions telling you where text appears on the page. You get blocks of text, but it's up to you to interpret what each block means and how they relate. DocuPipe is different: you define a schema with fields like invoice_number or line_items, and get structured JSON back with your exact field names. No post-processing required. This is why teams looking for structured document extraction often choose DocuPipe as their Textract alternative.
If you only need raw OCR text without any structure, have a team of AWS engineers with weeks to build the extraction pipeline, and don't need human review or audit trails, Textract is an option. But most teams processing business documents need more than raw text - they need structured data they can actually use.
DocuPipe is built for accuracy out of the box. Upload any document and get structured data back immediately - no training required. Amazon Textract requires custom Adapters for improved accuracy, which means providing 5 to 2,500 labeled documents and paying extra per page. With DocuPipe, you get high accuracy on day one across any document type. With Textract, you're investing time and money before you see any real results.
Absolutely. Some of our customers run AWS for everything else and use DocuPipe specifically for intelligent document processing. Store your extracted data in S3, trigger workflows with Lambda. You keep your AWS stack. You just don't have to struggle with Amazon Textract's async model and A2I integration. DocuPipe works as a drop-in Textract alternative without leaving all your other AWS systems behind.
Amazon Textract fragments its document extraction API by document type. Invoices go to AnalyzeExpense. IDs go to AnalyzeID. Mortgages go to AnalyzeLending. Each has different capabilities, pricing, and output formats. DocuPipe uses one unified intelligent document processing (IDP) API for everything. Define your schema once, extract from any document type. No routing logic, no endpoint juggling. Any format, any structure, almost any language (150+). This unified approach is why teams choose DocuPipe as their Amazon Textract alternative.
Most teams finish migrating from Amazon Textract to DocuPipe in a day. Same document formats, similar API patterns. The work is swapping AWS Textract API calls for DocuPipe document extraction API calls, and we're happy to hop on a call and help guide you through that.
AWS Textract defaults to 1-5 TPS depending on region. Getting higher throughput requires AWS support tickets and negotiation. DocuPipe enterprise plans offer custom capacity for high-volume intelligent document processing needs. Rate limits are a common reason teams evaluate Textract alternatives.
Yes. DocuPipe is SOC 2 Type II certified and ISO 27001 compliant. We sign BAAs for healthcare customers processing PHI. For organizations with the strictest data requirements, on-premise deployment keeps the entire document extraction pipeline inside your own compliant infrastructure - something Amazon Textract just can't offer.
Swap your Amazon Textract API calls for DocuPipe document extraction API calls. Document upload works similarly. Response is structured JSON. Most teams keep their existing doc handling and downstream logic.
It depends on your needs. DocuPipe is the best Textract alternative for teams that want simple integration, built-in human review, and predictable pricing without AWS infrastructure overhead. For raw OCR at scale with full AWS control, Textract still works. For AI-powered extraction with verification workflows, DocuPipe is purpose-built.



The best way to compare? Try it yourself.
Up to 20,000 free credits with an eligible work email. No credit card required.