8 min read
DocuPipe vs Amazon Bedrock: Which is best for your team? [2026]
Published March 14, 2026

Looking for the best Amazon Bedrock alternative for document extraction? Here's the difference: Bedrock gives you a raw LLM endpoint. You send PDFs to Claude, hit token limits on long documents, get rate-limited during spikes, and receive hallucinated JSON keys. Then you build SQS queues, retry logic, schema validators, and webhook infrastructure yourself. DocuPipe is a purpose-built document pipeline. Native OCR handles scans and faxes. Auto-chunking processes 2500+ page documents. Schema enforcement prevents hallucinations. Bedrock is a foundation model API. DocuPipe is production-ready document extraction.
TL;DR
Amazon Bedrock is a raw LLM endpoint. You build the OCR, chunking, and schema enforcement yourself. DocuPipe is a complete document pipeline - upload and get structured JSON back.
Table of Contents
- DocuPipe vs Amazon Bedrock at a glance
- Amazon Bedrock alternative: DocuPipe is a document pipeline, not a raw LLM
- No native OCR: why Bedrock fails on scanned documents
- Token limits cause truncation: Bedrock cannot handle long documents
- Hallucinated JSON keys: why LLMs fail at structured extraction
- No source traceability: Bedrock cannot show where data came from
- Build vs buy: the infrastructure you need around Bedrock
- Confidence scores: knowing when to trust your extractions
- Which should you choose?
- FAQ
DocuPipe vs Amazon Bedrock at a glance
| DocuPipe | Amazon Bedrock | |
|---|---|---|
| Best for | Teams shipping document extraction, not LLM infrastructure | Teams building custom AI applications from scratch |
| What you get | Complete document processing pipeline | Raw foundation model API endpoint |
| Document OCR | Native OCR for scans, faxes, photos | None - images and scans fail |
| Long documents | Handles 2500+ pages, splits automatically | Token limits cause truncation |
| Output quality | Your schema blocks hallucinated fields | Hallucinated JSON keys and values |
| Source traceability | source highlighting highlights exact source | None - no way to verify extraction |
| Infrastructure needed | API key + one endpoint | SQS, retry logic, validators, webhooks |
| Confidence scoring | Built-in confidence flags uncertain extractions | None - LLM outputs look equally confident |
| Webhooks | Svix webhooks built-in | Build it yourself |
Ready to see the difference?
Get up to 20,000 free credits with an eligible work email. No credit card required.
Amazon Bedrock alternative: DocuPipe is a document pipeline, not a raw LLM
Bedrock is not an extraction tool - it's a fully managed API service that gives you access to foundation models like Claude, Llama, and Titan. These models excel at semantic understanding: summarizing a 50-page legal contract, comparing clauses, translating text. But extraction requires something different.
Even multimodal models on Bedrock (like passing an image to Claude 3) don't natively output precise bounding boxes or understand spatial geometry. They're prone to hallucinating data and breaking strict JSON schemas when parsing dense tables. Plus you inherit all of AWS's complexity - SQS queues, IAM roles, Lambda functions - just to extract a document.
DocuPipe is purpose-built for structured extraction. Native OCR handles scanned documents. Auto-chunking processes 2500+ page documents. Schema enforcement guarantees your output structure. source highlighting traceability shows exactly where each value came from. Bedrock is a semantic reasoner. DocuPipe is an extraction pipeline.
No native OCR: why Bedrock fails on scanned documents
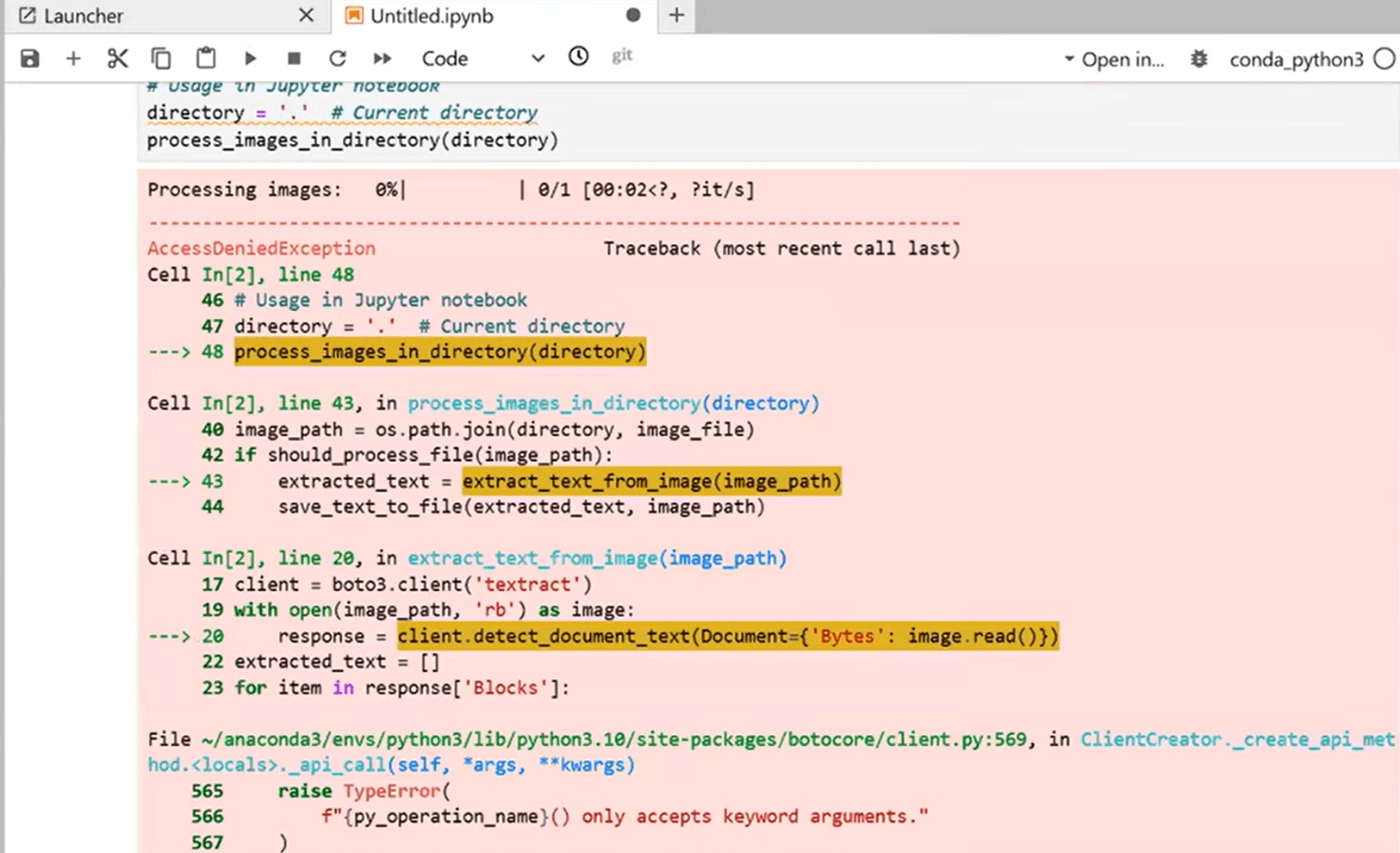
Amazon Bedrock's foundation models are powerful for text-based tasks. But they have a critical gap for document processing: no native OCR. Send a scanned invoice, a faxed contract, or a photo of a receipt, and the LLM cannot reliably read the text. You'll get partial extractions, garbled characters, or complete failures.
DocuPipe includes native OCR as part of the pipeline. Scanned PDFs, faxed documents, mobile photos - they all get converted to clean text before extraction. This isn't an add-on; it's built into how DocuPipe processes documents.
For teams processing real-world documents - which often include scans and faxes - this is a critical differentiator. You can try to wire up Amazon Textract before Bedrock, but now you're managing two AWS services, two sets of API calls, and the integration between them.
Token limits cause truncation: Bedrock cannot handle long documents
Send a 100-page contract to Amazon Bedrock and you'll hit token limits. The document gets truncated. Critical information at the end - signatures, final terms, appendices - simply disappears. The LLM processes what fits and ignores the rest, often without warning you that data was lost.
DocuPipe handles documents of any length through intelligent auto-chunking. Long documents are automatically split into processable segments, extracted separately, and reassembled into a coherent result. Your 100-page contract comes back complete, with every page processed.
For teams processing lengthy documents - contracts, medical records, legal filings - token limits are a dealbreaker. With Bedrock, you'd need to build your own chunking logic, manage context across segments, and handle reassembly. With DocuPipe, it just works.
Hallucinated JSON keys: why LLMs fail at structured extraction
LLMs hallucinate. Ask Claude via Bedrock to extract data into a specific schema, and sometimes it invents field names, makes up values, or returns completely fabricated information. Your code expects 'invoice_number' but receives 'invoiceNum'. You asked for a date but get a description. The LLM confidently returns wrong data.
DocuPipe prevents hallucinations through schema enforcement. You define your exact field names and types. The pipeline validates every extraction against your schema before returning results. If something doesn't match, you know immediately. No surprises in production.
This matters because document extraction feeds downstream systems. Databases, CRMs, ERPs - they expect consistent field names and valid data types. One hallucinated field name breaks your entire pipeline. DocuPipe's schema enforcement catches these errors before they propagate.
See it in action
Up to 20,000 free credits with an eligible work email. No credit card required.
No source traceability: Bedrock cannot show where data came from
When Claude via Bedrock extracts a value, how do you verify it's correct? You cannot. The LLM returns data with no indication of where on the document it found that information. For compliance, auditing, or simple quality assurance, this is a critical gap.
DocuPipe's source highlighting traceability shows exactly where each extracted value came from. Click any field in the review interface and see the exact text highlighted on the source document. Your team can verify extractions instantly. Auditors can trace any data point back to its source.
For regulated industries - healthcare, finance, insurance, legal - source traceability is not optional. You need to prove where data came from. With Bedrock, you're trusting the LLM. With DocuPipe, you're verifying against the source.
Build vs buy: the infrastructure you need around Bedrock
To use Amazon Bedrock for production document extraction, you need to build significant infrastructure. SQS queues for managing document throughput. Retry logic for handling rate limits and failures. Schema validators to catch hallucinated outputs. Webhook infrastructure for notifying downstream systems. Monitoring to track extraction quality.
DocuPipe includes all of this. Svix webhooks are built in. Rate limiting is managed automatically. Confidence scores flag uncertain extractions. The review interface handles human verification. You're not building infrastructure; you're extracting documents.
Calculate the engineering time to build Bedrock infrastructure versus the cost of a DocuPipe subscription. For most teams, it's not close. Building document extraction infrastructure on Bedrock takes months of engineering time. DocuPipe gets you to production in days.
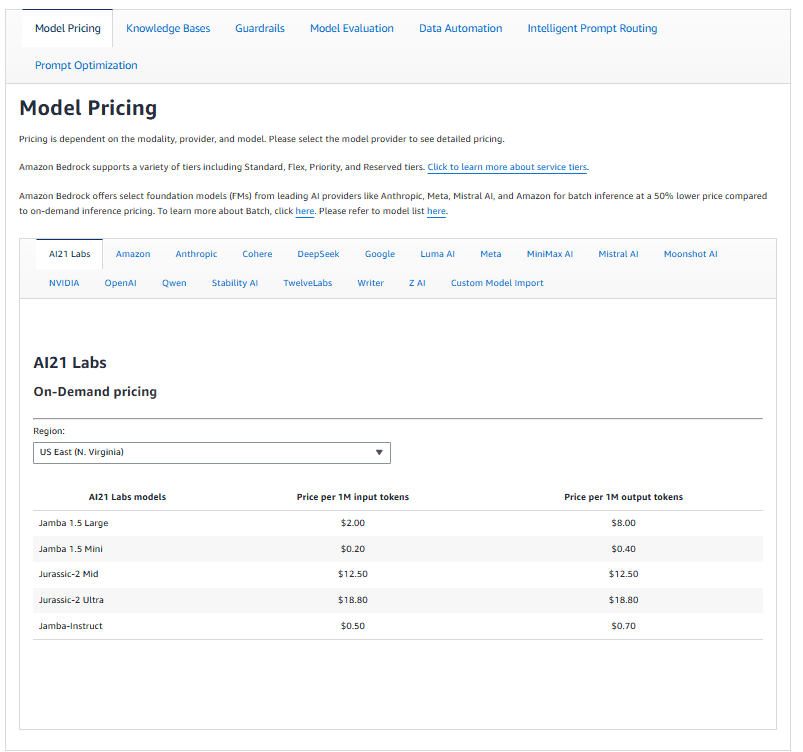
Confidence scores: knowing when to trust your extractions
LLM outputs all look equally confident. Claude via Bedrock returns data without any indication of certainty. A clearly printed invoice number and a smudged handwritten date both come back with the same apparent confidence. You have no way to know which extractions need human review.
DocuPipe includes confidence scoring for every extracted field. Low-confidence extractions are automatically flagged for human review. Your team focuses attention where it matters instead of reviewing everything or trusting everything blindly.
For high-stakes documents - medical records, legal contracts, financial statements - confidence scoring is essential. You need to know which extractions to verify. DocuPipe gives you that signal. Bedrock leaves you guessing.
Which should you choose?
Choose DocuPipe if...
You need structured extraction: specific fields into your database
You process dense tables, forms, or invoices requiring precise geometry
You need schema enforcement to prevent hallucinated outputs
You require source traceability for compliance or auditing
You want confidence scores to know which extractions need review
You don't want to build queuing, retry, validation, and webhook infrastructure
You need a production extraction pipeline, not a semantic reasoning API
Choose Amazon Bedrock if...
You need semantic reasoning: summarization, comparison, Q&A over documents
You're processing narrative-heavy documents (legal briefs, contracts for risk analysis)
You need to classify documents or identify specific clauses contextually
Your use case is document understanding, not structured data extraction
You're building RAG or chatbot features on top of documents
You already have separate OCR and extraction infrastructure
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
Amazon Bedrock is a raw foundation model API - you get access to LLMs like Claude and build everything else yourself. DocuPipe is a complete document extraction pipeline with native OCR, auto-chunking, schema enforcement, source traceability, confidence scoring, and webhooks built in. Bedrock is a building block. DocuPipe is a production-ready solution.
You can, but you'll face significant limitations. Claude via Bedrock cannot read scanned documents without separate OCR. Long documents hit token limits and get truncated. The LLM may hallucinate field names and values. You have no source traceability to verify extractions. You'll need to build queuing, retry logic, validators, and webhooks yourself. DocuPipe solves all of these problems out of the box.
LLMs like Claude are trained on text, not on reading images of text. When you send a scanned PDF to Bedrock, the model receives an image it cannot reliably interpret. You'll get partial extractions, errors, or failures. DocuPipe includes native OCR that converts scans to clean text before extraction, handling scanned documents, faxes, and photos reliably.
DocuPipe uses schema enforcement. You define your exact field names and types, and the pipeline validates every extraction against your schema. If the extraction doesn't match your schema, it's caught before returning results. Additionally, source highlighting traceability lets you verify exactly where each value came from on the source document.
For production document extraction with Bedrock, you typically need: SQS or similar queues for throughput management, retry logic for rate limits and failures, schema validators to catch hallucinations, chunking logic for long documents, OCR preprocessing for scans, webhook infrastructure for notifications, and monitoring for quality. DocuPipe includes all of this built in.
Yes. DocuPipe includes intelligent auto-chunking that handles documents of any length. Long documents are automatically split, processed, and reassembled. There are no token limits to worry about. With Bedrock, long documents get truncated and you lose data from the end of the document.
DocuPipe's source highlighting feature shows exactly where each extracted value came from on the source document. Click any field in the review interface and see the corresponding text highlighted on the original document. This enables verification, auditing, and compliance. Bedrock provides no source traceability - you simply have to trust the LLM's output.
When you factor in total cost of ownership, DocuPipe is typically less expensive. Bedrock charges per token, but you also need to build and maintain queuing, retry logic, validators, chunking, OCR integration, webhooks, and monitoring. That engineering time often costs more than DocuPipe's straightforward pricing. Plus DocuPipe's tiered credit system is predictable - no surprise bills from token spikes.
Use Bedrock when you need semantic reasoning over documents - summarization, comparison, Q&A, or classification. Bedrock excels at understanding narrative-heavy, unstructured documents: reading a legal brief to identify risk clauses, comparing contract terms, or answering questions about document content. If your use case is extracting specific fields into a database (invoice totals, vendor names, line items), DocuPipe is purpose-built for that. Different tools for different problems.
Most teams complete migration in a few days. You're actually removing complexity - no more managing queues, retry logic, validators, and chunking. Define your schemas in DocuPipe, update your API calls, and you're extracting documents. We offer migration support to help you transition smoothly.



The best way to compare? Try it yourself.
Up to 20,000 free credits with an eligible work email. No credit card required.