7 min read
DocuPipe vs LlamaParse: Which is best for your team? [2026]
Published March 10, 2026

Looking for the best LlamaParse alternative? DocuPipe vs LlamaParse comes down to this: LlamaParse feeds chatbots, DocuPipe feeds databases. LlamaParse outputs Markdown optimized for RAG pipelines and vector databases - great for AI search, but not for production software that needs structured data. DocuPipe gives you enforced JSON matching your exact schema. If you're building a chatbot or semantic search, LlamaParse works. But if you're building transactional software that needs reliable, validated data in your database, DocuPipe is what you need.
TL;DR
LlamaParse returns Markdown for RAG pipelines. DocuPipe returns enforced JSON schemas for transactional systems. Full IDP pipeline with classification and human review built in.
Table of Contents
- DocuPipe vs LlamaParse at a glance
- LlamaParse alternative: DocuPipe outputs database-ready JSON, not RAG-optimized Markdown
- Schema enforcement: LlamaParse hopes, DocuPipe validates
- Production IDP features: what LlamaParse doesn't have
- LlamaParse pricing: cheap standard mode, expensive accuracy
- LlamaIndex ecosystem: powerful for RAG, limiting for everything else
- Using LlamaParse standalone means building your own validation pipeline
- Which should you choose?
- FAQ
DocuPipe vs LlamaParse at a glance
| DocuPipe | LlamaParse | |
|---|---|---|
| Best for | Production software feeding databases | RAG pipelines feeding vector DBs |
| Primary output | JSON with your exact fields | Markdown for LLM consumption |
| Use case | Transactional document processing | Document Q&A and semantic search |
| Schema enforcement | Your fields, typed and validated | No - unstructured Markdown |
| Document classification | Built-in auto-detection | Not available |
| Document splitting | Automatic multi-doc splitting | Not available |
| Human review | Built-in UI with source highlighting | Not available |
| Webhooks | Built-in pipeline automation | Not available |
| Pricing | $99/mo Business, predictable | 7K free pages/week, then $0.003/page standard - agentic modes 10-45 credits/page |
Ready to see the difference?
Try DocuPipe free with 300 credits. No credit card required.
LlamaParse alternative: DocuPipe outputs database-ready JSON, not RAG-optimized Markdown
LlamaParse is fundamentally optimized for RAG pipelines, which means it defaults to Markdown output. The problem? Markdown destroys critical extraction metadata. It flattens complex multi-column layouts into linear text. It breaks merged table cells. It strips out confidence scores and positional data entirely.
For chatbots and document Q&A where you just need text chunks, that's fine. But for production software that needs structured data in databases, Markdown is the wrong output format. You can't reliably parse 'invoice_number' from freeform Markdown.
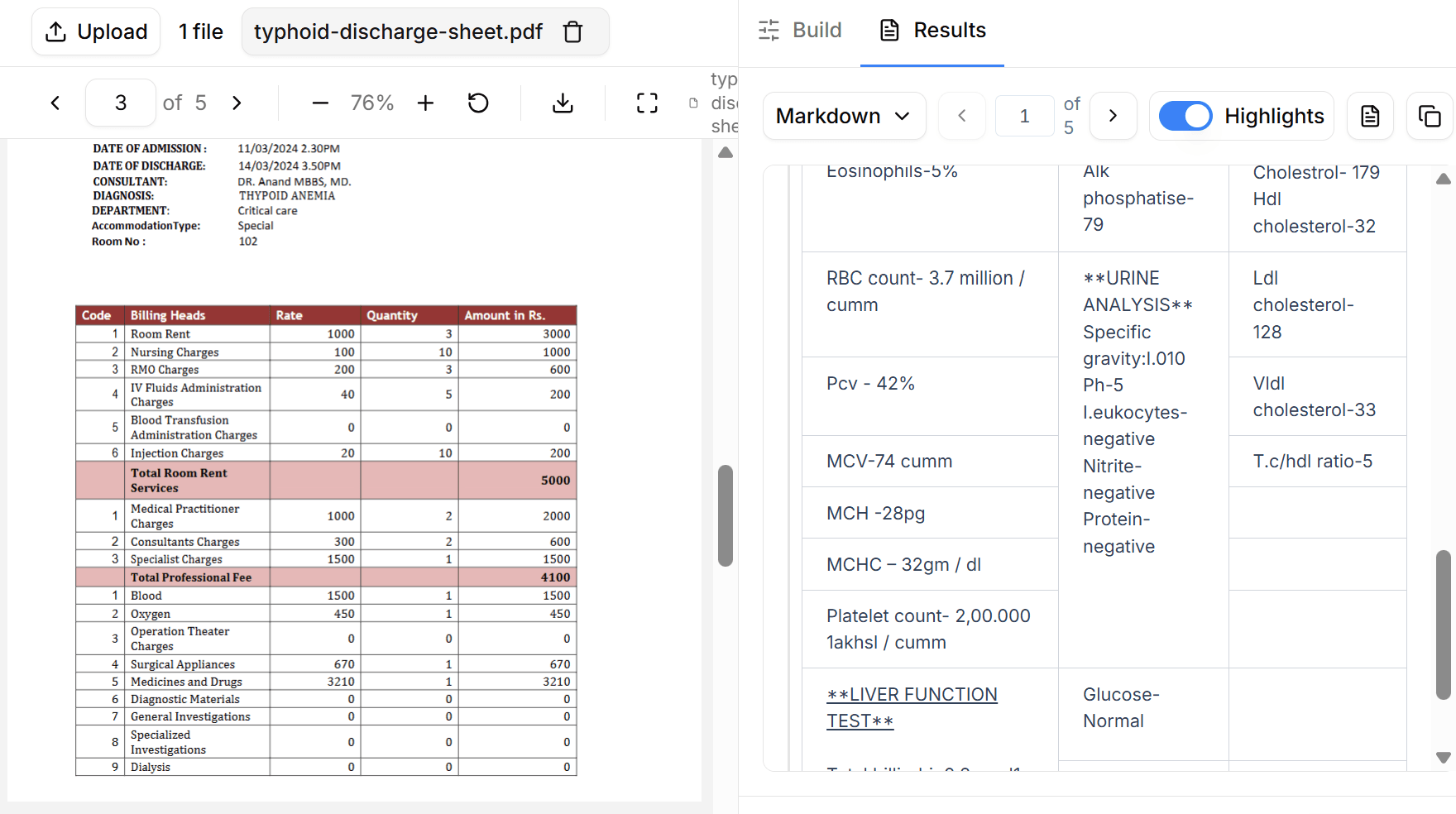
DocuPipe outputs database-ready JSON with your exact schema. Define fields like 'invoice_number', 'vendor_name', 'line_items' and get clean, validated JSON back. Confidence scores included. Positional data preserved. No parsing Markdown and hoping you got what you needed.
Schema enforcement: LlamaParse hopes, DocuPipe validates
LlamaParse previously offered structured extraction, but that capability has been deprecated - you now need a separate LlamaExtract service for schema-driven extraction. With LlamaParse alone, you get Markdown back, and it's up to you to parse it, validate it, and hope the structure matches what you expected. That means integrating multiple services for what should be a single workflow.
DocuPipe enforces your schema on every extraction in one unified API. Define 'invoice_date' as a date field, and you'll get a valid date or a flagged exception - never a random string that breaks your database. Define 'line_items' as an array, and you'll get a proper array structure every time.
This matters because production software can't handle 'mostly correct' data. When an invoice extraction sometimes returns the date as '2024-01-15' and sometimes as 'January 15th, 2024' and sometimes as 'the fifteenth', your downstream systems break. DocuPipe's schema enforcement eliminates that class of problems entirely.
Production IDP features: what LlamaParse doesn't have
LlamaParse is part of the LlamaIndex RAG framework - it's designed for data retrieval, not extraction accuracy. There's no native support for layout-aware parsing. No document classification capabilities. No built-in support for complex layouts, handwritten text, or contextual understanding. Teams must integrate additional tooling for batch-scanned documents, tables, and handwriting. Basic evaluation utilities only - accuracy testing sits outside the framework entirely.
No built-in schema versioning or change management. No workflow tools for production deployment. Requires significant custom engineering to achieve production-grade extraction accuracy. You'd need to build evaluation infrastructure from scratch.
Document classification? DocuPipe auto-detects document types and routes them to the right schema. Document splitting? DocuPipe automatically separates multi-document PDFs. Human review with source highlighting? Built in. Webhooks for pipeline automation? Schema dashboards for ops teams? Confidence scores for routing low-quality extractions? DocuPipe has all of this. LlamaParse gives you parsed documents - everything else is your problem to solve.
LlamaParse pricing: cheap standard mode, expensive accuracy
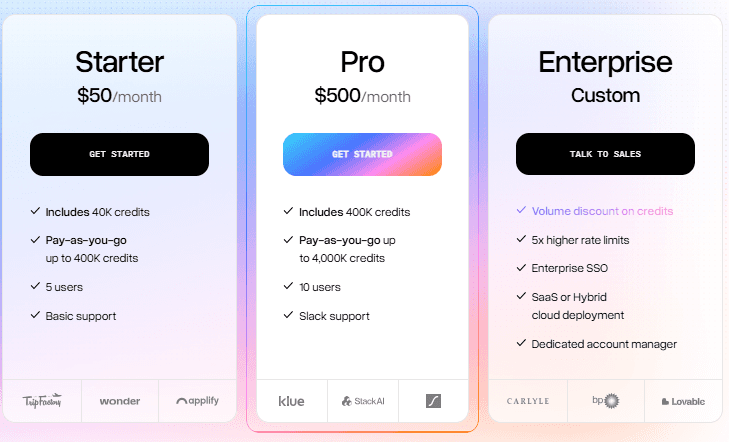
LlamaParse's pricing looks attractive at first: 7,000 free pages per week, then $0.003 per page for standard parsing. But that standard mode often isn't enough for production accuracy.
When you need higher accuracy, LlamaParse offers 'Agentic' parsing modes at higher price points. Their recommended Agentic mode runs 10 credits per page, while Agentic Plus runs 45 credits per page. For complex documents that need reliable extraction, you're paying 3-15x the standard rate.
DocuPipe uses predictable monthly pricing. Business plans start at $99/month with consistent per-page costs. You know what you'll pay whether you're processing invoices, contracts, or medical records. No surprise bills when your documents need more than basic parsing.
See it in action
300 free credits. No credit card required.
LlamaIndex ecosystem: powerful for RAG, limiting for everything else
LlamaParse is built for the LlamaIndex ecosystem. If you're using LlamaIndex for RAG applications, documents parse directly into LlamaIndex data structures, ready for indexing and querying.
But if you're not building RAG applications, that tight integration becomes a limitation. LlamaParse outputs are optimized for embedding and retrieval, not for database storage or API responses. You're adopting a tool designed for a use case that may not be yours.
DocuPipe is ecosystem-agnostic. Use the extracted JSON with any database, any API, any downstream system. Build RAG applications if you want - DocuPipe's structured output works there too. But you're not locked into a specific AI framework or use case.
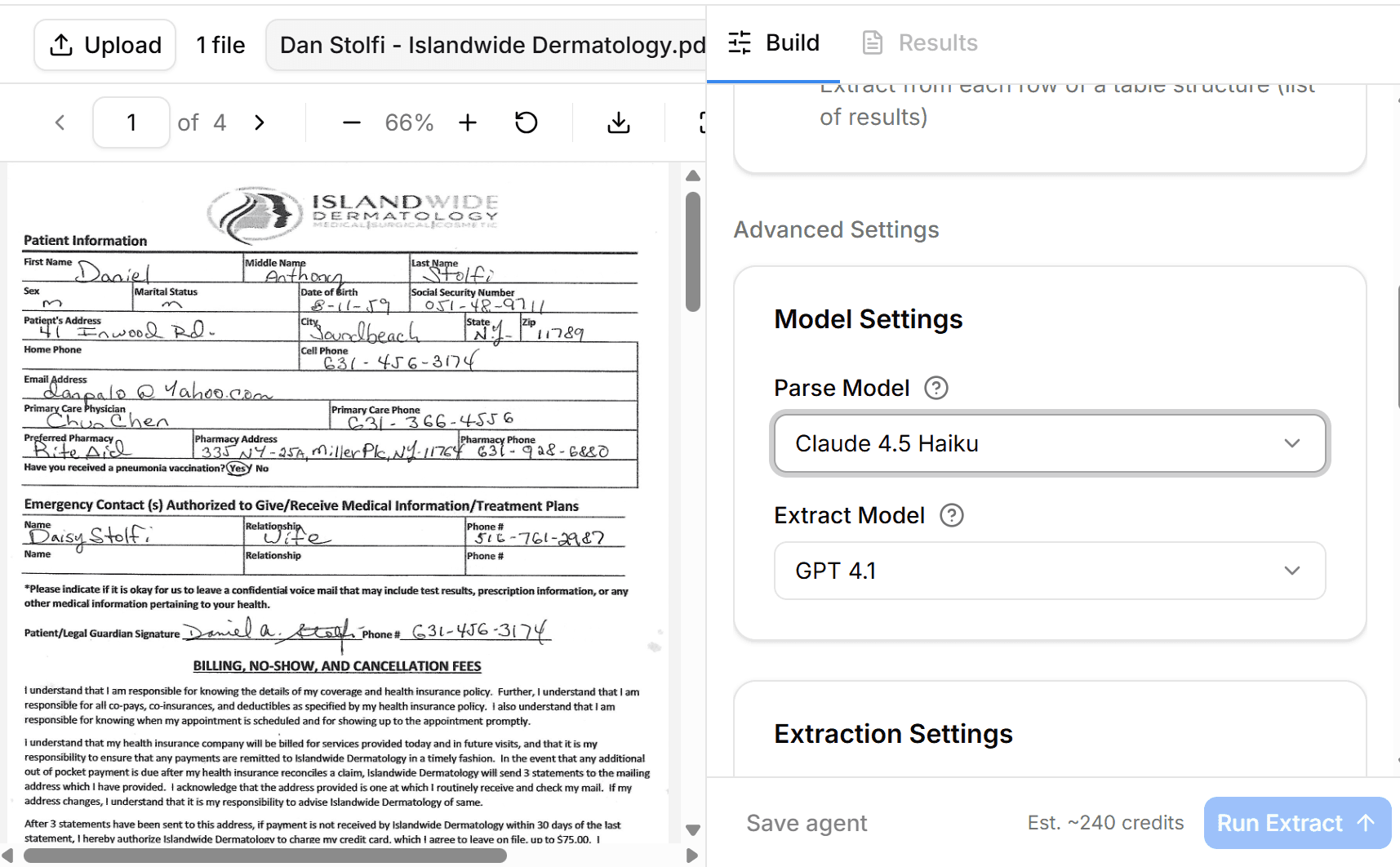
Using LlamaParse standalone means building your own validation pipeline
When you use LlamaParse outside of a LlamaIndex RAG pipeline, you're building infrastructure from scratch. Document routing? Write it yourself. Schema validation? Write it yourself. Error handling for malformed extractions? Write it yourself. Human review for low-confidence results? Build the entire UI yourself.
DocuPipe handles all of this out of the box. Documents flow through classification, extraction, validation, and review automatically. Exceptions get flagged. Low-confidence extractions route to human review. Validated results webhook to your systems.
For teams building production document processing, DocuPipe saves months of infrastructure work. For teams building RAG chatbots within LlamaIndex, LlamaParse's simpler scope might be all you need.
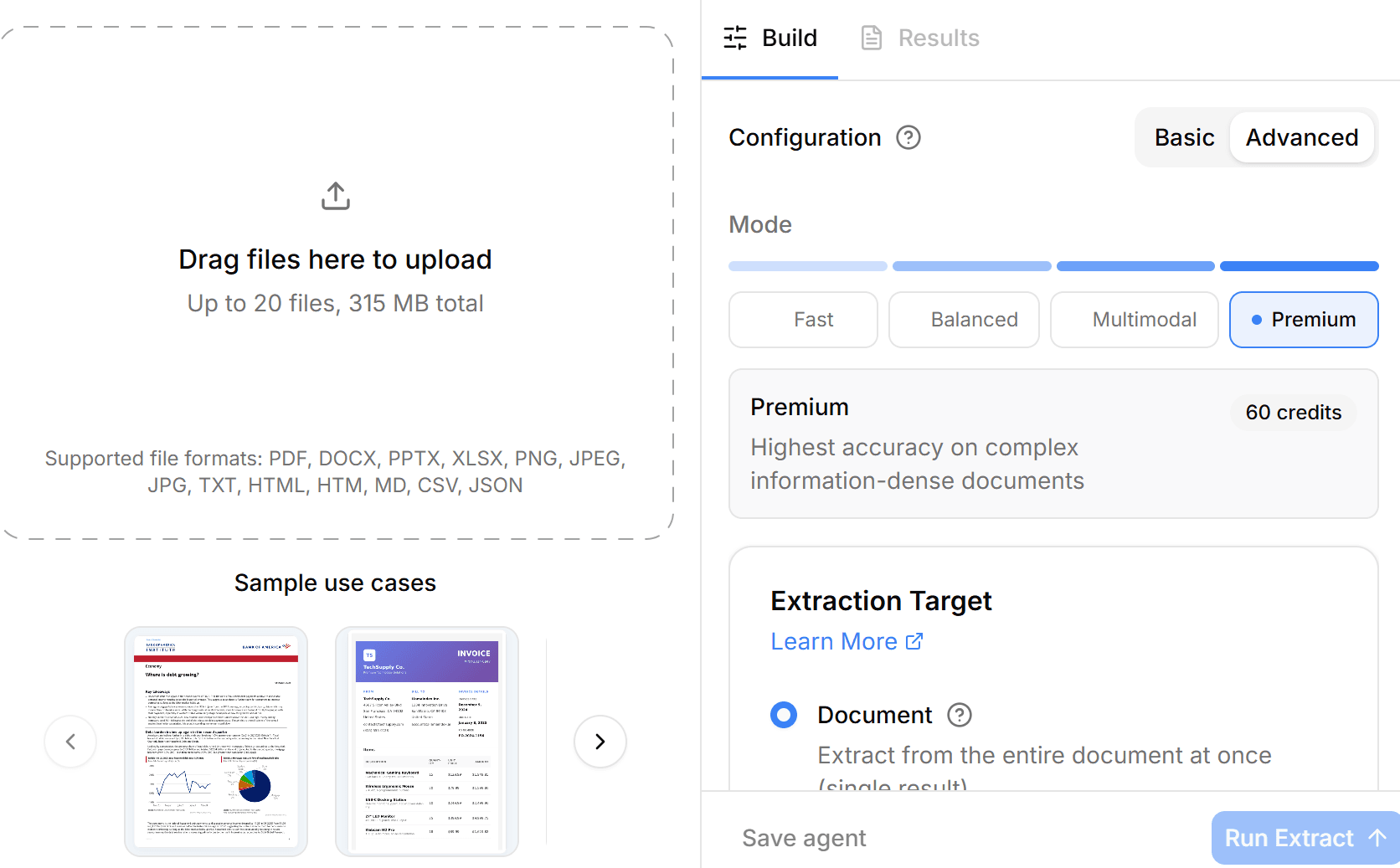
Which should you choose?
Choose DocuPipe if...
You need structured JSON data for databases, not Markdown for RAG
You want schema enforcement with validated field types
You need document classification and automatic routing
You need document splitting for multi-doc PDFs
You want human review with source highlighting built in
You need webhooks and pipeline automation
You want predictable monthly pricing
You're building transactional software, not chatbots
Choose LlamaParse if...
You're building RAG applications within LlamaIndex
You need Markdown optimized for embedding and retrieval
Your use case is document Q&A or semantic search
You don't need schema enforcement or validation
You're comfortable building classification, review, and routing yourself
Standard parsing accuracy is sufficient for your documents
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
LlamaParse outputs Markdown for RAG and vector databases. DocuPipe outputs enforced JSON for transactional software and databases. LlamaParse feeds chatbots. DocuPipe feeds production systems. If you're building document Q&A, LlamaParse works. If you're building software that processes documents and needs reliable structured data, DocuPipe is the better choice.
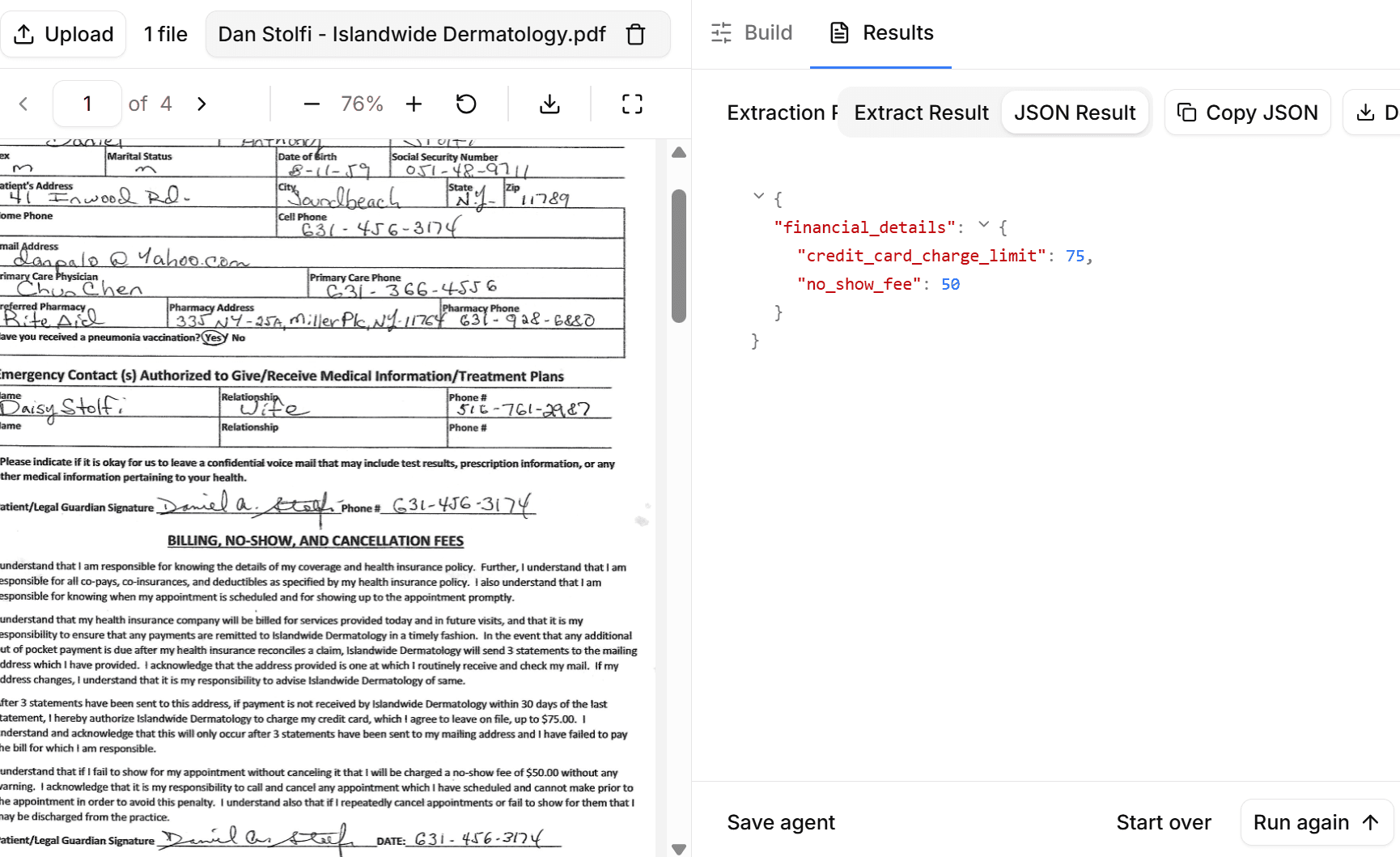
LlamaParse has a JSON mode, but it doesn't enforce schemas. You might get JSON back, but there's no guarantee it matches your expected structure. DocuPipe enforces your schema on every extraction - define 'invoice_number' as a string field, and you'll get that exact field name with validated data every time.
LlamaParse is focused on RAG applications within the LlamaIndex ecosystem - a much narrower use case than most document processing. If you're building a chatbot and don't care about structured extraction, LlamaParse exists for that. But most document processing is transactional - invoices, contracts, claims going into databases - and that requires schema enforcement, validation, and review. DocuPipe is built for real-world document workflows.
LlamaParse offers 7,000 free pages per week and standard parsing at $0.003 per page. But for production accuracy, you often need Agentic modes: their recommended Agentic mode costs 10 credits per page, Agentic Plus costs 45 credits per page. For complex documents, you're paying 3-15x the standard rate. DocuPipe's predictable monthly pricing avoids these surprises.
No. LlamaParse is a parsing tool, not a complete IDP pipeline. You'll need to build document classification yourself or use a separate service. DocuPipe includes automatic document classification that routes documents to the right schema without manual intervention.
No. LlamaParse doesn't include any review interface. If you need humans to verify extractions, you'll build that entire workflow yourself. DocuPipe includes the source highlighting review UI with source highlighting built in - your ops team can start reviewing documents immediately.
Yes. DocuPipe's structured JSON output works well for RAG pipelines. You can chunk and embed the extracted data just like any other content. The difference is you also get schema enforcement, classification, and review - features that help ensure the data going into your RAG system is accurate and validated.
Most teams migrate from LlamaParse to DocuPipe in a day or two. The main work is defining your schemas in DocuPipe and updating API calls. If you were already parsing LlamaParse output into structured data, DocuPipe eliminates that parsing code entirely.
Yes. Both DocuPipe and LlamaParse support PDFs, images, and common document formats. DocuPipe also supports 100+ languages for extraction, making it suitable for global document processing workflows.
DocuPipe is the best LlamaParse alternative for teams that need structured, validated data rather than Markdown for RAG. DocuPipe gives you enforced JSON schemas, document classification, splitting, human review, and webhook integrations - the complete IDP pipeline that LlamaParse doesn't provide.


The best way to compare? Try it yourself.
300 free credits. No credit card required.