
DOCUPIPE
Solutions
Resources
Pricing
Build vs Buy Document Processing: An Honest Guide (2026)
Uri Merhav
Updated Jan 17th, 2026 · 9 min read
Table of Contents
Build vs Buy Document Processing: An Honest Guide
With LLMs, building document processing platforms seems easier than ever. The reality is much more complicated.
The build vs buy decision for document processing comes down to whether your team should develop a complex in-house extraction system or purchase an Intelligent Document Processing (IDP) platform.
The build vs buy IDP question hits differently in 2026. LLMs made it possible to prototype a website concept in an afternoon, or an MVP for a document extraction tool in a day. But prototypes aren't by any means production systems, and the gap between a working demo and something that's actually reliable at scale is where most teams get stuck.
What You Need to Know
The appeal of building: Full control over the architecture, no vendor lock-in, and LLMs make extraction look deceptively simple to prototype.
The hidden cost: Getting to 90% accuracy is the easy part. That last 10% takes massive amounts of engineering, and maintenance never stops. And that last 10% is integral when it's the difference between paying a vendor $500.00 and $50,000, reading a patient's medical form correctly, or getting a shipment routed vs lost.
What LLMs actually changed: Zero-shot extraction works for simple cases. But LLMs don't give you confidence scores, bounding boxes, or reliability guarantees - when they're wrong, they are confidently wrong. And this makes sense, because they only know what they know.
Bottom line: If you're prototyping or have documents no vendor supports, building makes complete sense. But if accuracy matters and documents aren't your core product, you'll quickly hit a ceiling that can take years to surpass.
How LLMs Changed the Build vs Buy Equation
Five years ago, building document extraction systems meant training custom ML models for every single document type. LLMs completely changed that. With GPT-4, Gemini, or Claude, you can extract fields from a new document format without any training data.
But with that innovation came a problem: LLMs hallucinate when fed raw images or poorly parsed text. They don't tell you when they're uncertain, and they have no idea where on a page they found the information. When an LLM extracts "$50,000" from an invoice, you have no way to verify it actually read that number instead of inventing it.
Traditional document processing gives you confidence scores and bounding boxes, so you know how certain the system is and you can click a field to see exactly where the data came from. LLMs give you neither. In addition, they struggle with tables, multi-page documents, and anything that requires precise spatial understanding.
The real answer is using both together. Modern IDP platforms use traditional ML for parsing (OCR, layout detection, table extraction) and LLMs for the cognitive tasks (classification, field extraction from parsed text). Neither alone solves the entire problem.
The Hidden Costs of Building In-House
Getting to 90% accuracy isn't that hard. A decent engineer with access to GPT-4 can probably build a working prototype in a week. The problem is what comes after.
 Iceberg showing prototype as the small visible tip while production complexity lurks beneath
Iceberg showing prototype as the small visible tip while production complexity lurks beneathThe last 10% takes 10x the effort. Edge cases quickly multiply: handwritten annotations, rotated pages, inconsistent layouts, tables that span pages. Each one requires custom handling, and new ones never stop appearing.
Maintenance never really ends. Documents change. Vendors update their invoice formats again. New document types get added. Your extraction logic needs constant updates, and that becomes a constant responsibility.
The opportunity cost is real. Every engineer debugging document parsing is an engineer not focusing on your core product. Some sources estimate that it takes up to $1.8M in engineering labor over five years for a quality in-house build - and that's before you even account for what those engineers could have been building in that time instead.
You're flying completely blind. Without confidence scores, you have no idea which extractions to trust. Without bounding boxes, you can't show users where the data is coming from. You might get 90% accuracy, but you have no idea which 10% is fabricated. And building these features from scratch is its own multi-month project.
Take a look at the review of the low quality upload below. Without confidence scores, you'd have no way of knowing whether the system completely fabricated the data it's outputting, or actually identified that information correctly.
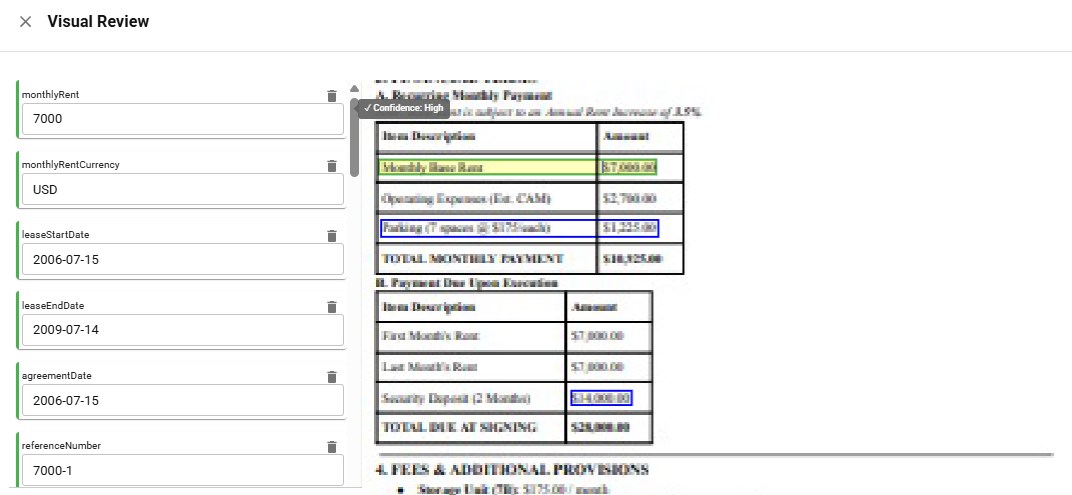 IDP platform extracting structured data from low-quality document scan with confidence scores showing extraction reliability
IDP platform extracting structured data from low-quality document scan with confidence scores showing extraction reliabilityWith confidence scores and bounding boxes, you can trust extractions even from poor quality scans and quickly verify where the information is coming from. Building this level of reliability from scratch is one of the places where the hidden costs of building end up piling up. What these costs all have in common is that they're invisible until you're already committed to the project. The prototype works great, and everything looks like it's operational. But the production system, building out a functional, useful, compliant system, is where teams often end up buried.
Should You Build Document Processing?
But building isn't always the wrong call. Here's where it actually does make sense:
You're prototyping or learning the problem space. Building a quick, low quality extraction pipeline will teach you what accuracy you actually need, which fields matter to you, and where your edge cases are. This knowledge will be super valuable if you eventually buy.
Your documents are genuinely unique. If you're processing document types that no vendor has seen before (extremely unlikely) - there is a small chance you need to build. But it's important to verify this is actually true before assuming it, as some platforms (ex. DocuPipe) are built specifically to handle nearly all formats and types.
Document processing is your core product. If you're building an IDP platform yourself, you obviously will need to build from scratch. But if documents are just an input to your actual product, that's an entirely different calculation.
Plenty of teams do start with GPT-4, learn what accuracy they need, then buy a solution when they hit their ceiling. That's a totally valid path - just don't expect the prototype to become production.
Build vs Buy: A Quick Decision Framework
If you're still not sure, here's a quick gut check.
Build if:
- You're prototyping to learn the problem
- Document processing is your actual product
- You have document types no vendor supports (extremely unlikely)
- You have ML engineers with spare capacity (even more unlikely) who want the project
Buy if:
- Accuracy above 95% is important to your work
- Documents are an input, not your core product
- You'd rather your engineers build features than maintain extraction pipelines
- You need confidence scores, audit trails, or any sort of working compliance features
| Factor | Build | Buy |
|---|---|---|
| Time to prototype | Days | Hours |
| Time to production | 6-18 months | Days to weeks |
| Accuracy ceiling | ~90% without major investment | 95-99%+ |
| Confidence scores | Build from scratch | Included |
| Maintenance | Permanent team responsibility | Vendor handles |
| Cost (5-year estimate) | $1-2M+ in engineering | $50-500K depending on volume |
Want to skip the build phase? Try DocuPipe free →
What to Look for in a Document Processing Vendor
If you've decided to buy, here's what separates solutions that work from those that make more problems.
| What to Look For | Why It Matters |
|---|---|
| Confidence scores | Know which extractions to trust vs review |
| Bounding boxes | Click a field, see exactly where it came from |
| Human-in-the-loop workflows | Catch errors before they hit your system |
| API-first architecture | Integrate into your stack, not a walled garden |
| Pre-trained on your document types | Faster accuracy out of the box |
| Transparent pricing | Volume-based, not surprises |
If you're embedding document processing into your product - serving your customers' documents and not just your own - the calculus obviously shifts. You need an API that handles document variability at scale, white-label options, and pricing that works when your customers are the ones uploading. It's important to select a platform built for this use case, not enterprise tools with an API poorly bolted on.
FAQ
A working prototype often takes weeks. Production-ready systems with high accuracy typically take up to two years, plus ongoing maintenance indefinitely.
Yes, for prototyping. LLMs handle zero-shot extraction well for simple cases. But they lack confidence scores, hallucinate when fed poorly-parsed text, and struggle with tables and multi-page layouts. Most teams hit a ceiling around 90% accuracy.
In-house builds typically plateau around 90% without a significant ML investment. Purpose-built IDP platforms achieve 95-99% accuracy right out of the box, with confidence scores to flag uncertain extractions.
Rarely. Engineering time adds up fast - estimates range from $1-2M+ over five years for an in-house build. Most IDP platforms cost a fraction of that, and you skip the maintenance burden entirely.
Buy. Buy unless document processing is your core product. Startups need to move fast and focus engineering on what differentiates them. Maintaining extraction pipelines is a total distraction from building your actual business.
OCR extracts text from images. IDP goes a step further - it classifies documents, extracts specific fields, validates data, and outputs structured JSON. OCR is a component of IDP, not a replacement for it.
Look for confidence scores, bounding boxes, human-in-the-loop workflows, and API-first architecture. Test with your actual documents, not just demos. And make sure to verify pricing scales with your volume.
When you've hit the accuracy ceiling and your engineers are spending more time on document parsing than your core product. Most teams reach this point much faster than they expect.
Key Takeaways
- LLMs changed the prototype game - building a demo is easier than ever, but production accuracy still requires specialized tooling
- The last 10% is where teams get stuck - edge cases, maintenance, and confidence scoring take years to solve in-house
- Building makes sense for prototyping - but most teams should switch to buying once accuracy matters
- Look for confidence scores and bounding boxes - these separate real IDP from LLM wrappers
- If documents aren't your core product, don't make them your engineering problem
Skip the build phase. See how DocuPipe handles your documents.
Recommended Articles
Related Documents