LLMs for Document Processing: What Works and What Doesn't
Uri Merhav
Updated Mar 26th, 2026 · 8 min read
Table of Contents
LLMs for Document Processing: What Works and What Doesn't
LLMs can extract data from documents without training - but given raw input, they hallucinate and lack confidence scores, which means errors slip through undetected. Here's what works.
Large language models (LLMs) are AI systems that read, interpret, and extract data from documents using natural language understanding rather than templates or pre-trained extraction models. This sounds almost magical, but LLMs come with tradeoffs that matter when accuracy is the goal. For a complete overview of IDP and how these technologies fit together, see What is Intelligent Document Processing.
What You Need to Know
In theory: It would be amazing if LLMs could extract data from documents without training examples (zero-shot), using simple English instructions instead of templates.
The problem: They hallucinate and can't provide confidence scores - so errors reach your systems undetected.
The fix: Modern IDP is built around LLMs - orchestrating many LLM calls across classification, extraction, and validation - but feeds them properly-parsed text from traditional ML (OCR, layout, tables) so they perform reliably.
Overall: LLMs enhanced document processing but did not replace it.
What Are LLMs?
Large language models are AI systems trained on massive text datasets to understand and generate human language. GPT-4, Claude, Gemini, and Llama are the well-known examples. Unlike traditional software that follows explicit rules, LLMs learn patterns from data and can respond to natural language instructions.
For document processing, this means that you can describe what you want extracted in plain English rather than building elaborate templates or writing complex code.
What LLMs Do for Document Processing
Zero-Shot Extraction
LLMs can extract fields from document types they've never seen. No training data, no prelabeled examples. Just a prompt describing what you need.
Natural Language Schemas
Instead of having to map coordinates or write regex, you can simply describe the fields in simple English: "Extract the vendor name, invoice total, and due date."
Unstructured Document Handling
Contracts, emails, medical notes. These are three examples of the many documents with no consistent layout that would break template-based extraction. LLMs can parse meaning from freeform text.
Summarization and Q&A
Beyond just extraction, LLMs can actually summarize documents or answer questions about their content.
This flexibility is real. But it comes with tradeoffs the moment you need production-grade accuracy.
Where LLMs Fall Short
Hallucinations
When fed raw images or poorly parsed text, LLMs confidently fabricate data. "rn" becomes "m", decimal points shift, numbers get invented. The danger: unlike traditional OCR which fails obviously, LLMs fail subtly. A wrong invoice total looks just as plausible as the correct one.
 Example showing how LLMs can misread characters and shift decimals, turning $70,000 into $700
Example showing how LLMs can misread characters and shift decimals, turning $70,000 into $700No Confidence Scores
LLMs can't communicate how sure they are - they have no built-in uncertainty mechanism. And they can't generate bounding boxes to show where they pulled data from.
Error Costs
Without confidence scores, you can't catch errors before they hit downstream systems. At 90% accuracy, 10% of your extractions are wrong - and you don't know which ones. Moving from 80% to 99.9% accuracy isn't just an improvement - it's the difference between needing human review on every document and blind automation.
LLMs + Traditional ML: What Each Does Best
| Capability | LLMs | Traditional ML |
|---|---|---|
| Zero-shot extraction | Yes | No |
| Confidence scores | No | Yes |
| Bounding boxes | No | Yes |
| Handles layout variations | Yes | Yes (with training) |
| Hallucination risk | Yes (when fed poorly) | No |
| Error visibility | None | Confidence scores |
Neither approach alone solves document processing. Standalone LLMs hallucinate. Traditional ML lacks semantic understanding. But LLMs fed properly parsed text are remarkably reliable. Modern IDP uses both: traditional ML handles parsing, LLMs handle extraction.
See how it works → Try DocuPipe free
The Hybrid Approach
The most effective IDP platforms are built around LLMs - potentially orchestrating hundreds of LLM calls per document, breaking complex problems into focused prompts. But they feed those LLMs properly-parsed text, not raw images.
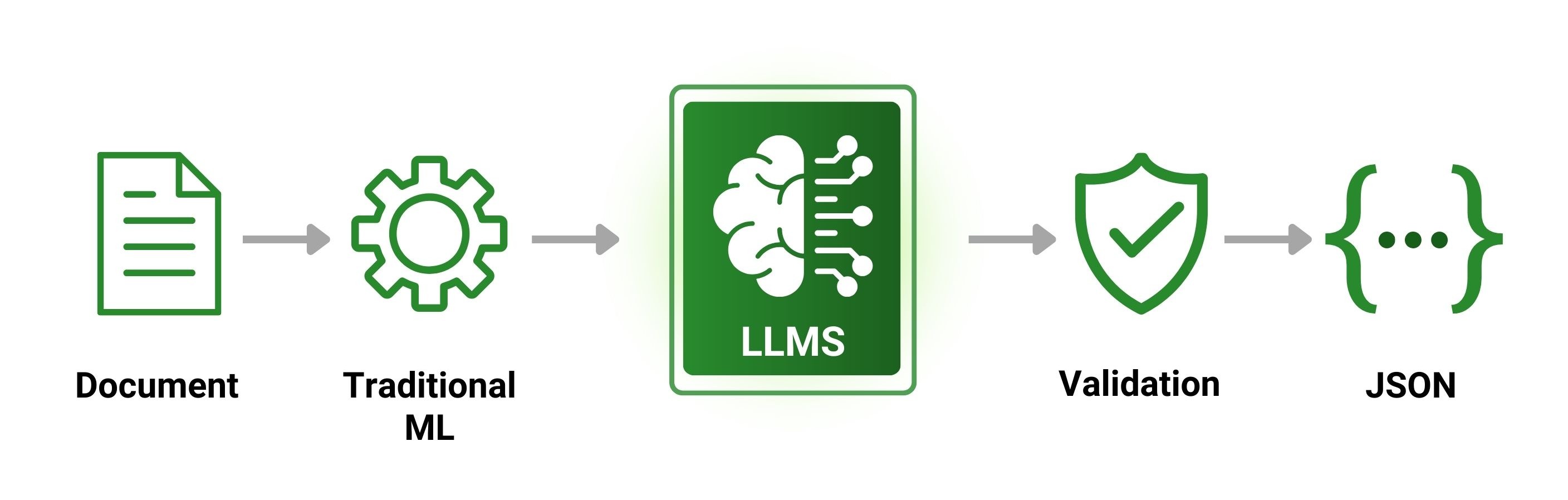 Hybrid IDP flow: document goes through Traditional ML for parsing, then LLMs for extraction, then validation, outputting structured data
Hybrid IDP flow: document goes through Traditional ML for parsing, then LLMs for extraction, then validation, outputting structured dataParsing (Traditional ML): OCR, layout detection, table parsing, checkmark detection, and signature recognition. Traditional ML is more accurate than LLMs for these tasks and doesn't hallucinate text that isn't there.
Classification (LLMs): Identifying document types without needing training examples upfront.
Extraction (LLMs): Once the document is parsed, LLMs extract the actual field values from both structured layouts and unstructured text.
Splitting (LLMs): Separating multi-document PDFs into individual documents.
Validation: Business rules and confidence thresholds catch hallucinations before bad data reaches downstream systems.
This layered approach gives you the best of both worlds. Traditional ML handles the parsing layer where precision matters most. LLMs handle classification, extraction, and splitting where their flexibility shines. Validation catches what either might miss.
Building this infrastructure from scratch requires deep expertise in both traditional ML and LLM orchestration. That's why most teams use IDP platforms instead of assembling the entire stack themselves. If you're building a SaaS product and evaluating document processing APIs, see our guide to document processing APIs for SaaS.
When the Hybrid Approach Is Optimal
The hybrid approach (traditional ML for parsing, LLMs for extraction) works best when you need both accuracy and flexibility.
LLMs add the most value when:
- You're processing new document types with no training data (zero-shot)
- Documents are unstructured (contracts, emails, freeform notes)
- You need summarization or Q&A over document contents
Traditional ML parsing is critical when:
- Audit trails and bounding boxes are required
- Documents have complex tables, checkboxes, or signatures
- You need reliable OCR without hallucination risk
In a hybrid system, you get both. Traditional ML provides the accurate, grounded text with bounding boxes. LLMs process that text intelligently for downstream tasks.
FAQ
Yes, but with crippling limitations. ChatGPT can extract data from PDFs when given the text, but it can't provide confidence scores, may likely hallucinate values or facts, and has no way to show where data came from in the original document.
They can - especially given raw images or bad OCR. Decimal points shift, characters get swapped, numbers get invented. Without validation, these errors pass through undetected. But fed properly-parsed text, LLMs are remarkably reliable.
They solve different problems. OCR converts images to text, while LLMs understand what that text means and extract specific fields. Modern document processing uses traditional ML for parsing (OCR, layout detection, table parsing) because it's more accurate and doesn't hallucinate, then hands that parsed content to LLMs for classification and extraction.
LLMs handle the classification, extraction, splitting, and review layers in modern IDP systems. Traditional ML handles the parsing layer (OCR, layout detection, table parsing, checkmarks, signatures) because it's more accurate and doesn't hallucinate. Validation rules catch errors before data reaches downstream systems.
No confidence scores, no bounding boxes, and hallucination risk when fed poorly. LLMs work best as part of a hybrid system, not as standalone extraction tools.
Use both. Modern IDP platforms use traditional ML for parsing (OCR, layout detection, table extraction) because it's accurate and doesn't hallucinate. Then LLMs handle classification and extraction of the actual field values. The best platforms layer them together.
No. LLMs enhance IDP but they can't replace it. They lack abilities and features that are fundamental to IDP: confidence scores, reliable data when fed properly-parsed text, validation, bounding boxes, and audit trails.
Zero-shot extraction: Pulling data from a document type the system has never seen before, with no previous training examples. LLMs enable this by following natural language instructions rather than relying on pre-built templates. This is why modern IDP that utilizes LLMs are so useful.
Key Takeaways
- LLMs enable zero-shot extraction - no training data needed for new document types
- LLMs hallucinate when fed poorly - but they're reliable when given clean, properly-parsed text
- No confidence scores or bounding boxes - you can't verify where data came from
- Accuracy unlocks automation - 80% means human review on everything; 99.9% means blind automation
- Hybrid is the answer - modern IDP uses traditional ML for parsing, LLMs for extraction
- Use both - traditional ML for accurate parsing, LLMs for flexible extraction
LLMs are powerful tools. But power without precision is just guessing - and you won't know which guesses are wrong until it's too late.
Ready to process documents with accuracy?
Recommended Articles
Related Documents
Related documents:
Related documents:
RIB
CT-e
Non-Disclosure Agreement
BAS
Check
Invoice
NDA
NF-e
UAE Labor Contract
DPA
Title Insurance Policy
T4 Slip
Fit Note
Rent Roll
SAFE Note
+