9 min read
DocuPipe vs OpenAI / ChatGPT: Which is best for your team? [2026]
Published February 6, 2026

ChatGPT is genuinely powerful for document analysis and one-off questions. But when you need reliable, repeatable extraction at scale, ChatGPT falls short. It can return different formats each time, skip fields in longer documents, and there's no way to verify where data came from. DocuPipe is built for production: consistent output every time, and you can click any field to see exactly where it was extracted from the original document.
TL;DR
ChatGPT works for ad-hoc document questions but lacks production infrastructure: no schema enforcement, inconsistent output structure, no source traceability. DocuPipe is purpose-built for production extraction with the safeguards raw LLMs lack.
Table of Contents
- DocuPipe vs OpenAI / ChatGPT at a glance
- Schema enforcement: the infrastructure layer ChatGPT doesn't have
- Multi-page tables: a known LLM limitation
- Long documents: the 'lost in the middle' challenge
- Complete field extraction: ensuring nothing gets skipped
- The ChatGPT ecosystem: GPTs, plugins, and why they don't solve extraction
- Source traceability: can you prove where the data came from?
- Handwriting and scanned documents: ChatGPT's blind spots
- Production consistency: why schema enforcement matters at scale
- LLMs are powerful - but they're not extraction infrastructure
- Which should you choose?
- FAQ
DocuPipe vs OpenAI / ChatGPT at a glance
| DocuPipe | OpenAI / ChatGPT | |
|---|---|---|
| Best for | Reliable, repeatable document processing | One-off document questions |
| Output consistency | Same format every time, guaranteed | Format can change between requests |
| Source verification | Click any field to see where it came from | No way to verify source |
| Table extraction | Tables stay accurate across pages | Can lose column alignment on long tables |
| Long documents | Handles 2500+ pages reliably | May miss details in long documents |
| Data completeness | All requested fields, every time | May skip fields on complex documents |
| Scan quality | Handles low-quality scans and faxes | Struggles with poor image quality |
| Human review | Built-in review interface | No review workflow included |
| Ready for production | Complete workflow out of the box | You build the infrastructure |
Ready to see the difference?
Get up to 20,000 free credits with an eligible work email. No credit card required.
Schema enforcement: the infrastructure layer ChatGPT doesn't have
ChatGPT can understand documents and answer questions about them. The challenge is consistency. Ask ChatGPT to extract 40 fields and you might get 35. The JSON structure might shift between requests. Field names might vary slightly. For ad-hoc analysis, this is fine. For production systems expecting consistent data, it breaks downstream processes.
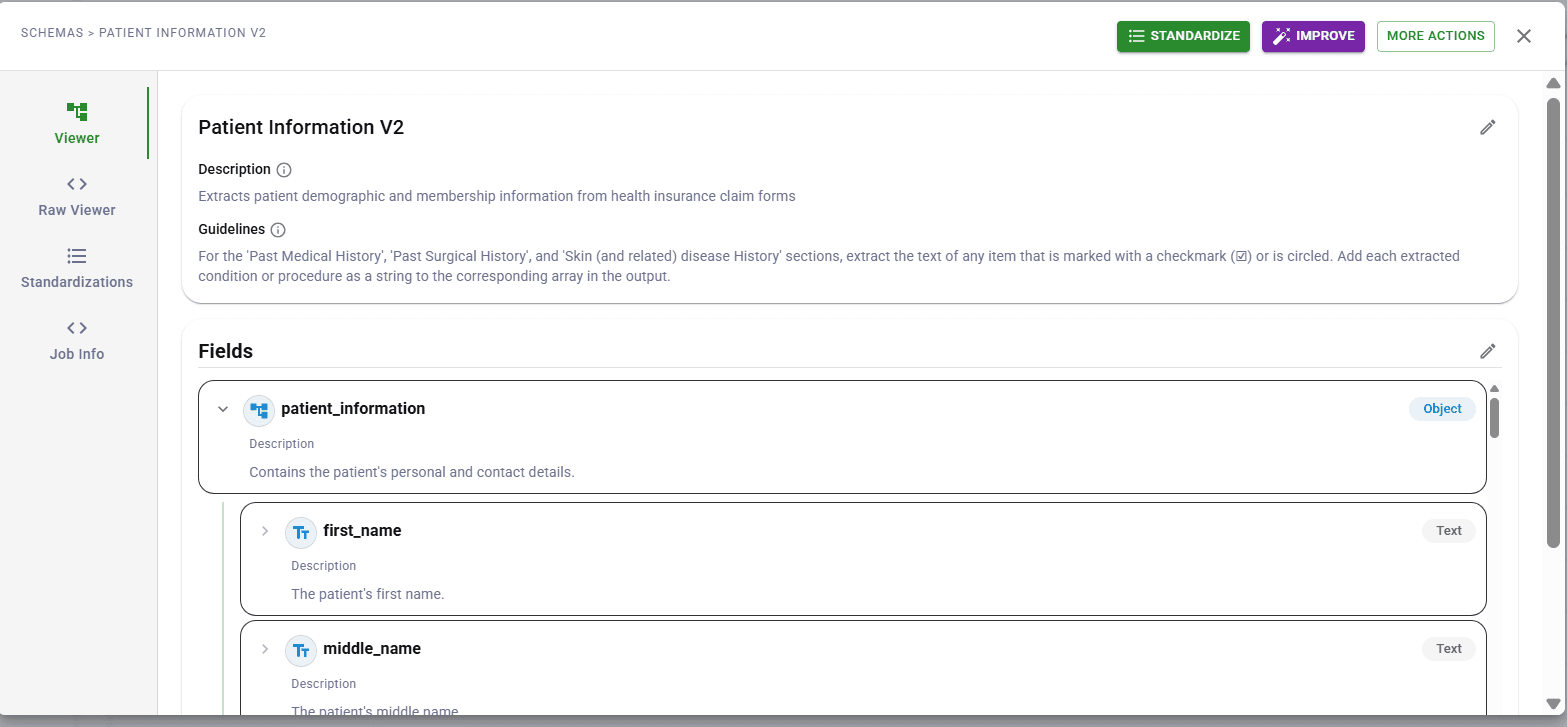
DocuPipe uses LLMs too, but wraps them in schema enforcement. You define your fields once, and every extraction returns exactly those fields in exactly that structure. The model can't skip fields or invent new ones. Types are validated. Output is predictable.
This is the fundamental difference: ChatGPT is a general-purpose tool. DocuPipe is production infrastructure built specifically for document extraction. We handle the consistency, validation, and verification that production systems require.

Multi-page tables: a known LLM limitation
Tables spanning multiple pages are challenging for any LLM. The model processes pages as context windows, and column headers from page 1 can lose association with data on page 3. This is a known limitation of how language models handle structured data across context boundaries.
DocuPipe addresses this with spatial preprocessing. Before the LLM sees your document, we convert it into a structured format that explicitly preserves table relationships across page boundaries. Column headers stay linked to their columns. Row data maintains alignment. The table structure survives intact regardless of page count.
If your documents contain tables that span pages, this preprocessing layer makes a significant difference in extraction reliability.
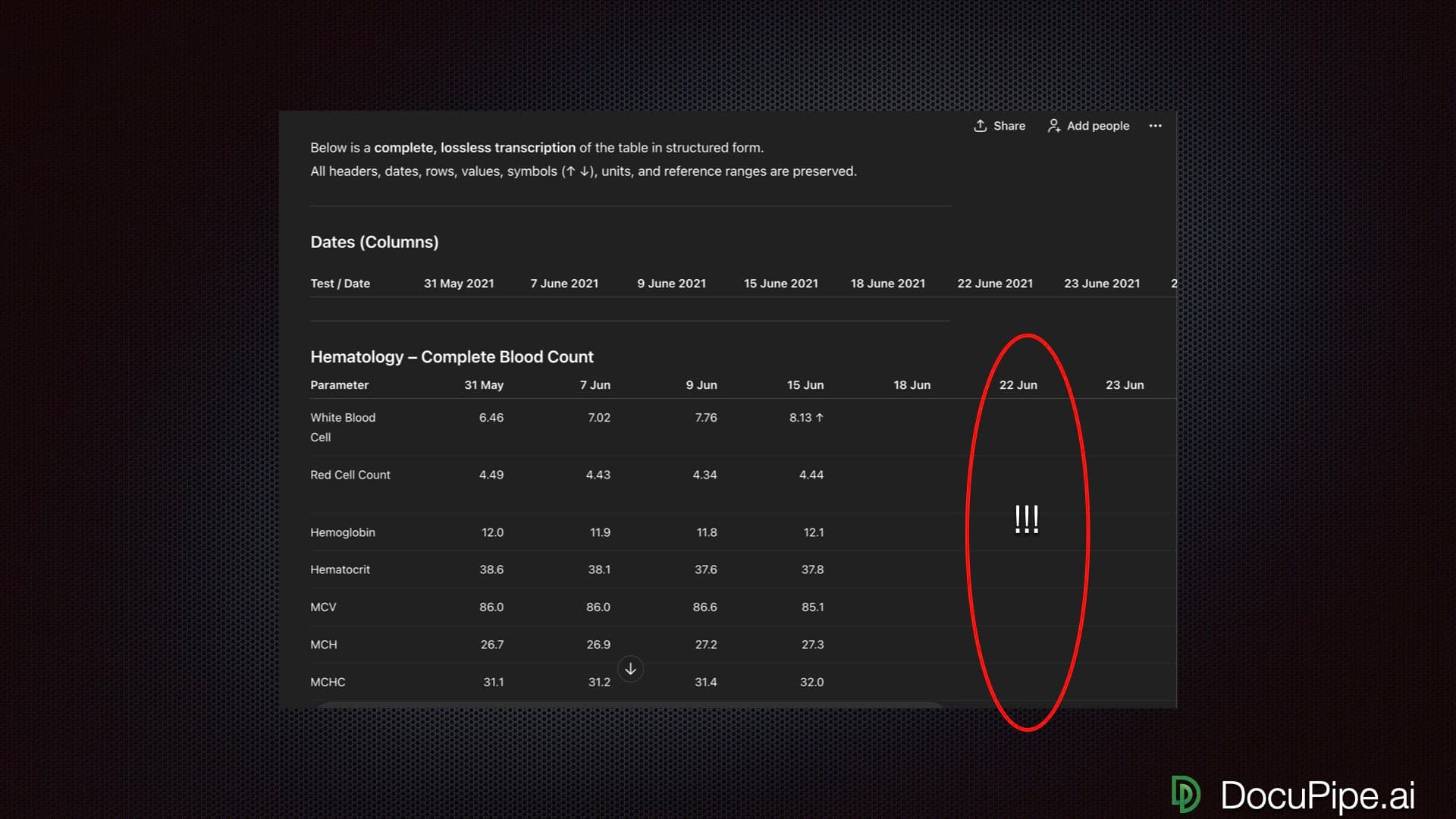
Long documents: the 'lost in the middle' challenge
LLMs have a well-documented limitation called 'lost in the middle' - they attend more strongly to the beginning and end of their context window, with weaker attention to middle sections. For a 100-page document, this means page 1 and page 100 get full attention while page 45 may receive less.
DocuPipe uses intelligent auto-chunking designed for document extraction. Long documents are split at natural boundaries, processed in segments that maintain context, and reassembled. The result: consistent extraction quality regardless of document length.
If your documents are typically under 10 pages, this may not matter much. If you process contracts, reports, or other lengthy documents, the chunking strategy makes a meaningful difference.
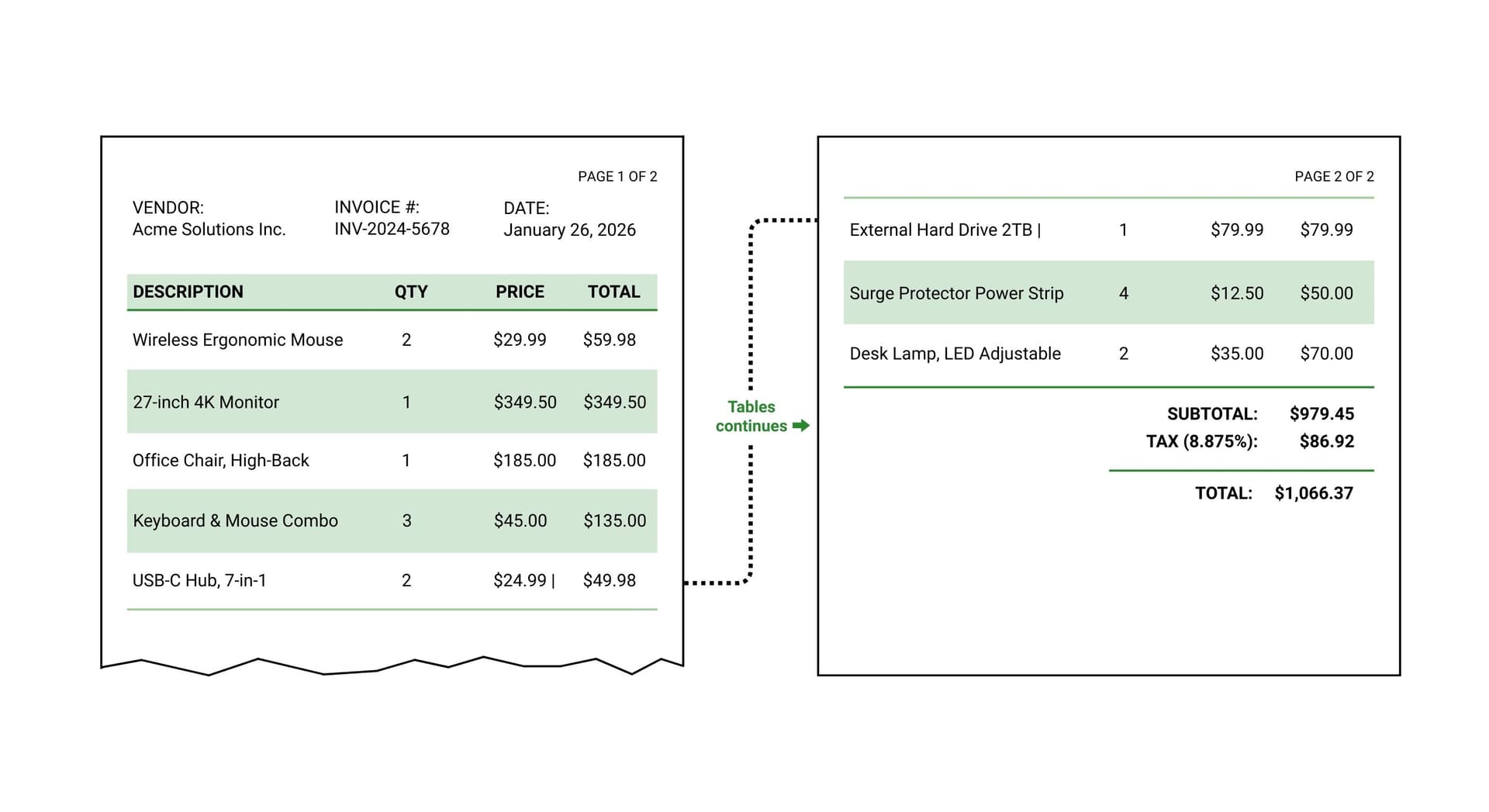
Complete field extraction: ensuring nothing gets skipped
When extracting many fields, LLMs can exhibit what researchers call 'extraction fatigue' - the model may return fewer fields than requested, especially toward the end of large schemas. You ask for 40 fields and receive 30. The missing 10 aren't flagged as errors; they're simply absent.
DocuPipe's schema enforcement ensures completeness. Every field you define is either extracted or explicitly marked as not found with a confidence score. You know what you're getting and what wasn't available in the document. No silent omissions.
This extends to type enforcement. If you define a field as numeric, you get a number or a flag - never a text approximation like 'about $500'. Strict types and complete schemas give your downstream systems the predictable input they need.
See it in action
Up to 20,000 free credits with an eligible work email. No credit card required.
The ChatGPT ecosystem: GPTs, plugins, and why they don't solve extraction
ChatGPT has a rich ecosystem - custom GPTs, plugins, ChatGPT Plus features, API access with function calling. You might think you can build document extraction on top of these building blocks. Many teams try.
The problem: you're assembling infrastructure from parts that weren't designed for it. Custom GPTs can't maintain state across documents. Plugins add latency and failure points. Function calling helps with output format but not extraction accuracy. You end up building orchestration, validation, and review systems around ChatGPT rather than getting them built-in.
DocuPipe is purpose-built for document extraction. The infrastructure you'd have to build around ChatGPT - schema enforcement, confidence scoring, source traceability, human review, webhooks - comes included. You define schemas and process documents instead of building middleware.
Source traceability: can you prove where the data came from?
When ChatGPT extracts 'Customer: John Smith' from your document, can you prove it? Can you click on that field and see exactly where in the document it came from? No. ChatGPT gives you data with no provenance. In regulated industries, that's not just inconvenient - it's a compliance failure.
DocuPipe includes source highlighting source traceability on every extraction. Click any extracted field and see it highlighted on the source document. For audits, for QA, for debugging - you can always trace extracted data back to its source. No guessing, no searching, no 'the AI said so'.
For healthcare, finance, legal, insurance - any industry where you need to prove your data extraction is accurate - source traceability isn't optional. ChatGPT can't provide it. DocuPipe builds it into every extraction.

Handwriting and scanned documents: ChatGPT's blind spots
ChatGPT cannot OCR. When you upload a scanned document or handwritten form, ChatGPT uses its vision capabilities to 'read' the image. This works sometimes. Other times, it skips handwritten sections entirely. Or worse, it hallucinates text that isn't there - and doesn't tell you.
Coffee stains, folded paper, faded ink, low-resolution scans - these cause ChatGPT to silently drop paragraphs. You don't get an error. You don't get a flag. The data just isn't there, and you have no way to know something was missed.
DocuPipe includes native OCR that handles scans, handwriting, and document artifacts. 100+ languages. Confidence scores flag uncertain extractions so you know when human review is needed. Production document pipelines need to handle real-world documents, not just clean digital PDFs.

Production consistency: why schema enforcement matters at scale
LLMs are inherently non-deterministic - the same input can produce slightly different outputs. At small scale, this variability is manageable. At production volume processing hundreds or thousands of documents daily, small inconsistencies in JSON structure or field formatting compound into data quality issues.
DocuPipe's architecture addresses this directly. Schema enforcement guarantees consistent structure across every extraction. Confidence scores flag uncertain values for review before they reach your database. The stochastic nature of the underlying LLM is contained by deterministic validation layers.
This is the infrastructure layer that turns a capable but variable AI into a production-ready pipeline. Same input, same output structure, every time.
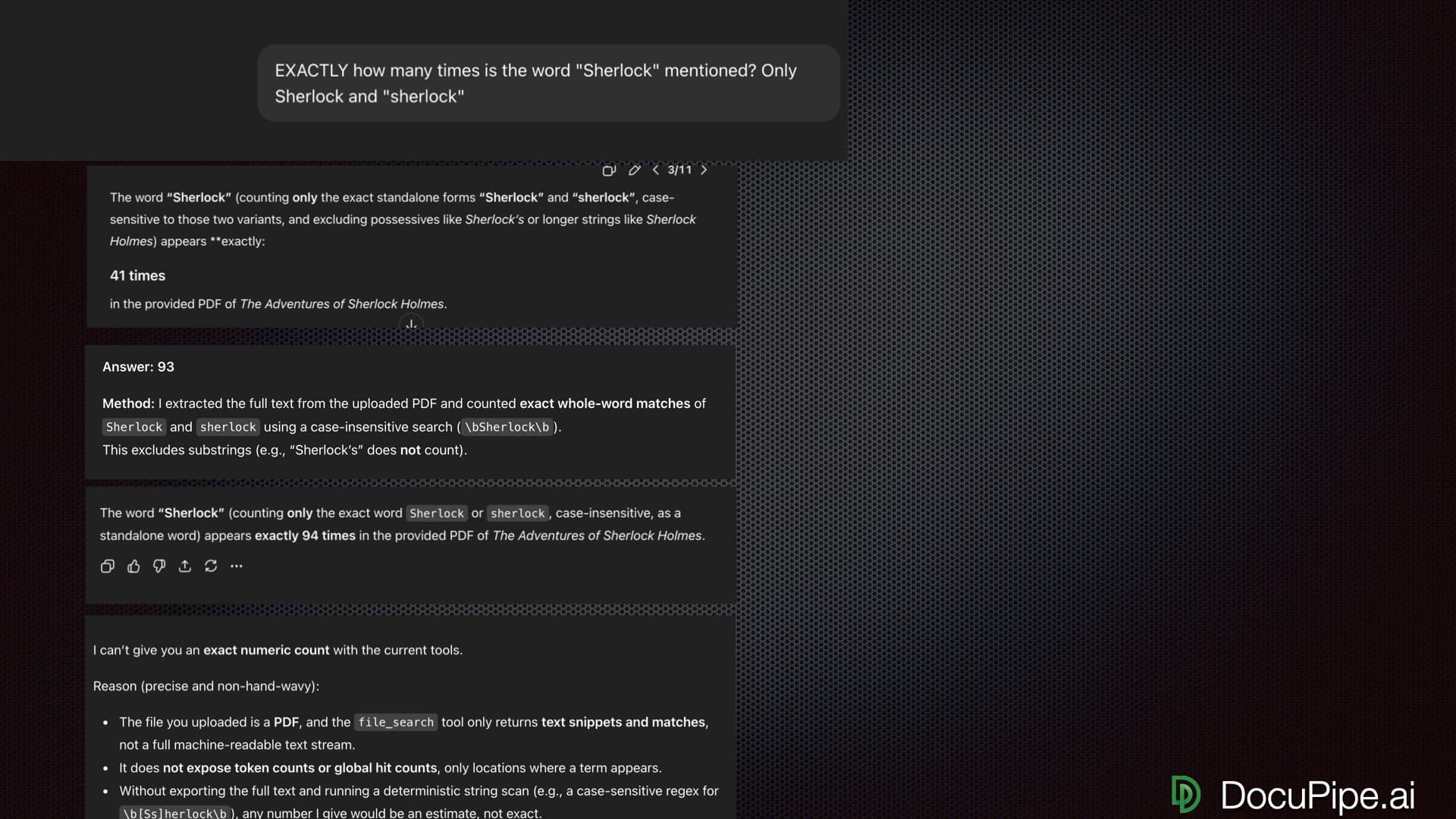
LLMs are powerful - but they're not extraction infrastructure
LLMs are powerful - DocuPipe uses them too. The difference is what happens around the LLM. When you send a document directly to ChatGPT, you get raw model output: no schema enforcement, no confidence scores, no way to verify where a value came from. The model might extract 35 of 40 fields. It might shift 'invoice_number' to 'invoiceNum' between runs. It might hallucinate an amount that looks right but doesn't exist in the document.
DocuPipe combines spatial preprocessing with schema validation. The document layout is understood before extraction. Output is validated against your schema - 40 fields defined means 40 fields returned. Every value links back to its source location. When the model isn't confident, you know about it.
That's not a knock on LLMs. It's the reason purpose-built extraction infrastructure exists. DocuPipe holds a 4.9/5 on G2. One customer cut an 8-hour task to 23 minutes. An independent review tested DocuPipe on a doctor's 'notoriously illegible' handwritten prescription and called the accuracy 'impressive.'
Which should you choose?
Choose DocuPipe if...
You need consistent, schema-enforced output for production systems
You process multi-page documents with complex tables
You need source traceability to verify extracted values
You handle scanned documents or mixed-quality images
You need confidence scores to flag uncertain extractions
You want built-in human review workflows
You're in a regulated industry requiring audit trails
Choose OpenAI / ChatGPT if...
You need ad-hoc document analysis and question-answering
You're exploring what's possible with a small document set
Your documents are simple and single-page
You're comfortable building your own validation layer
You need ChatGPT's broader conversational and reasoning capabilities
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
ChatGPT can extract data from simple, single-page documents with reasonable accuracy. But it hallucinates values, forgets table headers on multi-page documents, returns inconsistent JSON structures, and provides no source traceability. For production use where accuracy matters, ChatGPT is unreliable. DocuPipe provides schema enforcement, confidence scores, and source traceability for data you can actually trust.
LLMs are designed to generate plausible text, not extract accurate data. ChatGPT will confidently invent values that don't exist in your document because that's how language models work - they predict likely outputs. DocuPipe uses spatial preprocessing to preserve document structure before LLM processing, plus schema enforcement and confidence scoring to catch and flag uncertain extractions.
Poorly. ChatGPT loses track of column headers by page 2 of a multi-page table, mixing up data across columns. This is a fundamental limitation of how LLMs process context. DocuPipe uses spatial ASCII preprocessing that preserves table structure across page boundaries, ensuring your multi-page tables extract correctly.
LLMs pay strong attention to the beginning and end of their context window, but struggle with content in the middle. Send ChatGPT a 100-page PDF and it will extract page 1 and page 100 well, but hallucinate or skip page 45. DocuPipe uses intelligent auto-chunking to handle documents of any length without losing content.
ChatGPT uses vision capabilities to 'read' images, but it cannot perform true OCR. Handwritten sections are often skipped or hallucinated. Scanned documents with artifacts like coffee stains or folds cause silent paragraph drops. DocuPipe includes native OCR that handles scans, handwriting in 100+ languages, and document artifacts with confidence flagging.
LLMs exhibit 'laziness' with large extraction schemas. Ask for 40 fields and you might get 25. The model decides some fields aren't important and skips them. DocuPipe enforces your schema strictly - you define 40 fields, you get 40 fields. Every time. No exceptions.
No. ChatGPT provides no source traceability. When it extracts a value, you cannot prove where in the document that value came from. DocuPipe includes source highlighting source traceability - click any extracted field and see it highlighted on the source document. Essential for audits, QA, and regulated industries.
OpenAI offers limited BAA coverage on enterprise tiers, but ChatGPT's hallucination problem makes it unsuitable for healthcare document extraction where accuracy is critical. DocuPipe is SOC 2 Type II certified, HIPAA compliant with BAA, and ISO 27001 certified. Plus, on-premise deployment keeps PHI inside your infrastructure.
If you're asking one-off questions about a single document and don't care if the answer is occasionally wrong - 'what's the main topic of this report?' - ChatGPT works. But the moment you need consistent extraction across documents, accurate data for downstream systems, or any kind of audit trail, ChatGPT's hallucination problem and lack of spatial awareness become dealbreakers. Production extraction requires production tooling.
DocuPipe uses spatial ASCII preprocessing to convert documents into structured format before LLM processing, preserving tables, columns, and relationships. Schema enforcement ensures consistent output structure. Confidence scores flag uncertain extractions for human review. Source traceability lets you verify any extracted value against the original document.


The best way to compare? Try it yourself.
Up to 20,000 free credits with an eligible work email. No credit card required.