8 min read
DocuPipe vs Google Gemini: Which is best for your team? [2026]
Published February 14, 2026

Gemini handles long documents well and offers competitive pricing for document analysis. But when you need reliable extraction at scale, you'll have to build the infrastructure yourself. Output formats can change between requests, there's no way to verify where data came from, and no built-in review workflow. DocuPipe is the complete package: consistent output every time, click any field to see where it came from, and a review interface your team can use today.
TL;DR
Gemini has large context windows and multimodal capabilities, but lacks production extraction infrastructure: no schema enforcement, no source traceability, no built-in review workflows. DocuPipe is purpose-built for production extraction with the safeguards raw LLMs lack.
Table of Contents
- DocuPipe vs Google Gemini at a glance
- Google Gemini alternative: DocuPipe enforces schemas, Gemini shifts them
- Hallucination handling: why Gemini extractions can't be trusted
- Source traceability: DocuPipe shows where data came from, Gemini doesn't
- Gemini's massive context window: why 1M tokens doesn't solve extraction
- Long documents: auto-chunking vs hoping the model pays attention
- Production-ready features: what Gemini lacks for real workflows
- Human-in-the-loop: DocuPipe's built-in review vs building your own
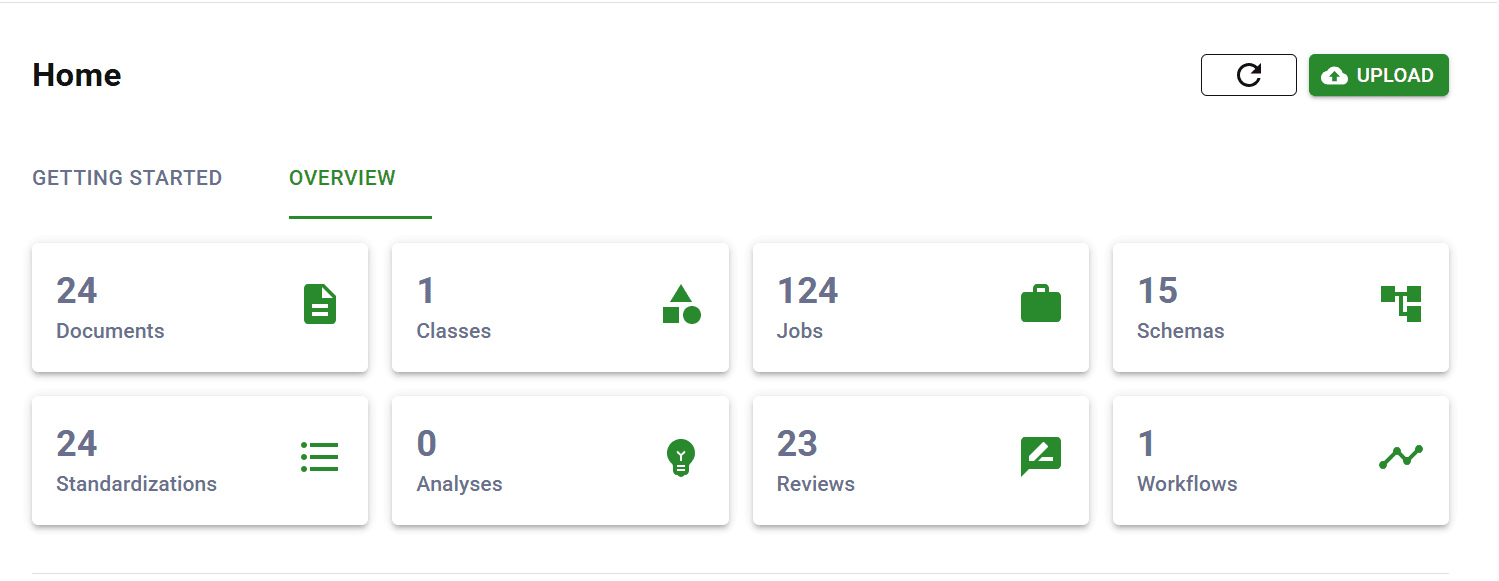
- LLMs are powerful - but they're not extraction infrastructure
- Which should you choose?
- FAQ
DocuPipe vs Google Gemini at a glance
| DocuPipe | Google Gemini | |
|---|---|---|
| Best for | Reliable, repeatable document processing | Document analysis and Q&A |
| Long documents | Handles any length automatically | Handles long documents natively |
| Output consistency | Same format every time, guaranteed | Format can change between requests |
| Source verification | Click any field to see where it came from | No way to verify source |
| Data completeness | All requested fields, every time | May skip fields on complex documents |
| Human review | Built-in review interface | You build it yourself |
| Multi-document PDFs | Auto-splits into separate records | Not available |
| Notifications | Built-in webhook notifications | Not available |
| Pricing | Predictable pricing at any scale | Competitive per-use pricing |
Ready to see the difference?
Get up to 20,000 free credits with an eligible work email. No credit card required.
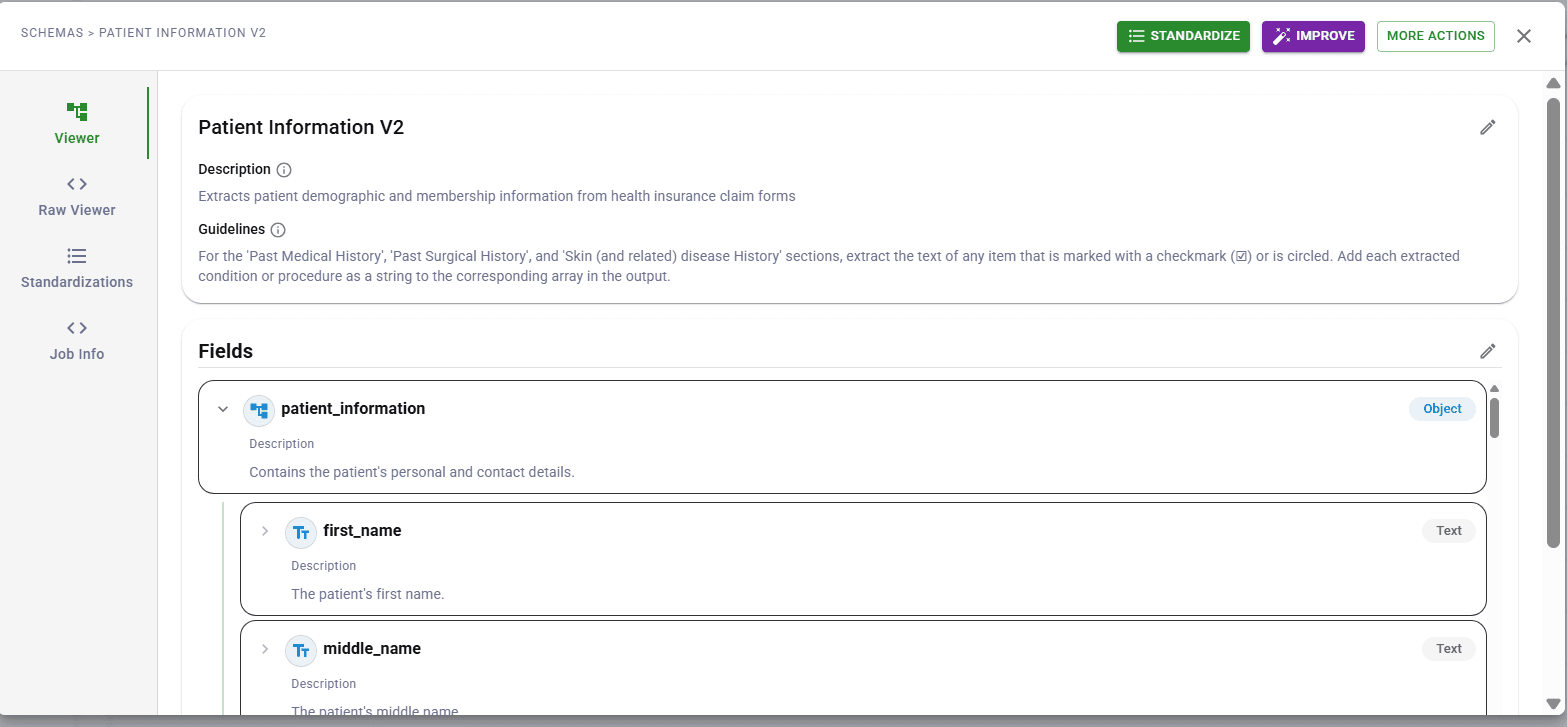
Google Gemini alternative: DocuPipe enforces schemas, Gemini shifts them
The fundamental difference between DocuPipe and Google Gemini for document extraction: Gemini requires you to build the orchestration layer yourself. Document preprocessing, chunking, retry logic, error handling, schema validation - that's all on you. And Gemini struggles with nested JSON output on large batches, returning malformed structures that break your parsers.
Google Gemini has no schema enforcement. Ask it to extract data today, and you might get 'invoiceNumber'. Tomorrow, 'invoice_num'. Next week, 'InvoiceID'. The JSON structure shifts between runs, sometimes omitting fields, sometimes adding unexpected ones. These shifting schemas corrupt your database over time.
DocuPipe handles the entire pipeline end-to-end. Define your schema once - fields like 'invoice_number', 'vendor_name', 'line_items' - and get that exact structure back every single time. No orchestration to build, no nested JSON failures, no late-night debugging sessions.
Hallucination handling: why Gemini extractions can't be trusted
Like ChatGPT and Claude, Google Gemini suffers from the same hallucination problem that affects all general-purpose LLMs. When the model isn't sure, it makes things up. For document extraction, this means fabricated invoice numbers, invented dates, and amounts that don't exist in the source document.
DocuPipe's spatial preprocessing prevents hallucinations at the architecture level. The system understands document layout - where tables start and end, how columns align, which text blocks belong together. This spatial awareness means extractions come from actual document content, not LLM imagination.
For regulated industries like healthcare, insurance, or finance, hallucinated data isn't just inconvenient - it's a compliance violation. DocuPipe's deterministic extraction ensures every field traces back to actual document content. With Gemini, you're hoping the LLM didn't make things up.

Source traceability: DocuPipe shows where data came from, Gemini doesn't
When your ops team questions an extraction, they need to verify it against the source. DocuPipe's source highlighting feature highlights exactly where each field came from on the original document. Click any extracted field and see it highlighted in context. Verification takes seconds.
Google Gemini provides no source traceability. The model outputs extracted data, but there's no way to trace it back to specific locations in the document. Your ops team has to manually scan the source document to verify each field - assuming the data wasn't hallucinated in the first place.
For audit trails and compliance, this difference is critical. DocuPipe's built-in traceability gives you defensible extractions. With Gemini, you're building your own verification system or accepting unverifiable data.

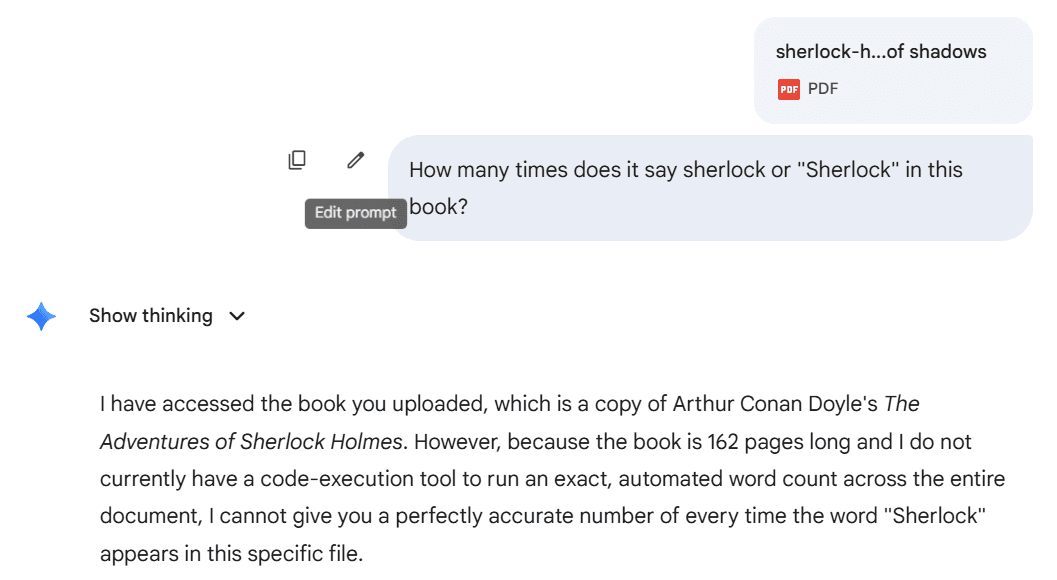
Gemini's massive context window: why 1M tokens doesn't solve extraction
Gemini's headline feature is its massive context window - up to 1 million tokens, far exceeding ChatGPT or Claude. You might think this solves the long document problem. You can fit entire books in a single prompt. Why would you need DocuPipe's auto-chunking?
Context window size doesn't fix attention distribution. The 'lost in the middle' problem persists regardless of how much text the model can accept. Large context windows let you fit more content, but the model still attends unevenly across that content. Middle sections get less attention than beginnings and ends.
DocuPipe's auto-chunking is designed for extraction quality, not just content fitting. We split documents at semantic boundaries, process each segment with full attention, and reassemble results. You get consistent extraction quality across every page, not just the pages near the beginning and end of your prompt.
See it in action
Up to 20,000 free credits with an eligible work email. No credit card required.
Long documents: auto-chunking vs hoping the model pays attention
Even with Gemini's large context window, the attention distribution problem remains. A 100-page document fits in the context, but does the model give equal attention to page 1, page 50, and page 100? Research consistently shows it doesn't.
DocuPipe handles long documents through intelligent auto-chunking. Documents are split into manageable segments while preserving context - especially important for tables spanning pages. Every section gets full processing attention, so nothing gets lost.
For teams processing lengthy contracts, multi-page invoices, or comprehensive reports, this matters. With Gemini, you're relying on the model's uneven attention distribution. With DocuPipe, you get systematic coverage regardless of document length.
Production-ready features: what Gemini lacks for real workflows
Beyond extraction quality, production document processing requires features that Google Gemini simply doesn't offer. DocuPipe includes document classification to automatically detect document types, document splitting to separate multi-doc PDFs, and Svix webhooks for event-driven architectures.
Need human review? DocuPipe's built-in review UI lets your team verify extractions with source highlighting. Need confidence scores? Every field includes confidence metrics so you know when to route for human review. Need consistent output? Deterministic processing ensures reliability.
Google Gemini is a general-purpose AI assistant. It can extract data from documents, but it's not built for production document processing workflows. No classification, no splitting, no webhooks, no review UI, no confidence scores. You'll build all of this yourself - or you'll choose DocuPipe.
Human-in-the-loop: DocuPipe's built-in review vs building your own
For many document processing workflows, human verification is non-negotiable. DocuPipe ships with visual review built in. Click any extracted field and see exactly where it came from on the source document, highlighted in yellow. Your ops team can start verifying extractions today with zero technical setup.
Google Gemini offers no review interface. You get extracted data as text output with no visual connection to the source document. Building a review system means creating UI for document viewing, annotation, field highlighting, and audit trails - weeks of development work.
For regulated industries, audit trails matter. DocuPipe's built-in verification workflow handles compliance requirements out of the box. With Gemini, you're building that compliance layer from scratch - assuming you can even trace extractions back to source content.
LLMs are powerful - but they're not extraction infrastructure
LLMs are powerful - DocuPipe uses them too. The difference is what happens around the LLM. When you send a document directly to Gemini, you get raw model output: no schema enforcement, no confidence scores, no way to verify where a value came from. The model might extract 35 of 40 fields. It might shift 'invoice_number' to 'invoiceNum' between runs. It might hallucinate an amount that looks right but doesn't exist in the document.
DocuPipe combines spatial preprocessing with schema validation. The document layout is understood before extraction. Output is validated against your schema - 40 fields defined means 40 fields returned. Every value links back to its source location. When the model isn't confident, you know about it.
That's not a knock on LLMs. It's the reason purpose-built extraction infrastructure exists. DocuPipe holds a 4.9/5 on G2. One customer cut an 8-hour task to 23 minutes. An independent review tested DocuPipe on a doctor's 'notoriously illegible' handwritten prescription and called the accuracy 'impressive.'
Which should you choose?
Choose DocuPipe if...
You need consistent JSON schemas that don't shift between runs
Your ops team needs to verify extractions against source documents
You're building production systems where hallucinations cause real problems
You process long documents and can't afford to lose middle content
You need document classification and splitting
You want human review with source highlighting built in
You need confidence scores for automated quality control
You require webhooks for event-driven architectures
Choose Google Gemini if...
You're doing exploratory document analysis or one-off extractions
You can build and maintain your own validation and review layers
You need Gemini's broader reasoning capabilities beyond structured extraction
You don't need to trace extractions back to source locations
You're prototyping before committing to production infrastructure
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
Google Gemini is a general-purpose LLM without schema enforcement. Each inference is probabilistic - the model generates what it thinks you want based on the prompt, not what you specified. Field names, structure, and completeness vary between runs. DocuPipe enforces your schema at the system level, guaranteeing consistent output every time.
Yes. Like ChatGPT and Claude, Gemini hallucinates - inventing data when uncertain. For document extraction, this means fabricated values that don't exist in the source. DocuPipe's spatial preprocessing prevents hallucinations by grounding extraction in actual document content with full source traceability.
Gemini often loses context when tables span page boundaries, resulting in incomplete or misaligned data. DocuPipe's spatial preprocessing maintains table continuity across pages, ensuring complete and accurate table extraction regardless of document length.
No. Gemini provides extracted text without source location information. DocuPipe's source highlighting feature highlights exactly where each field came from on the original document. Click any extracted field and see it highlighted in context - essential for verification and compliance.
When extracting many fields, Gemini often returns partial data due to attention limitations and context constraints. DocuPipe's intelligent document processing ensures complete extraction of all schema fields, every time.
No. Gemini is a general-purpose AI without built-in document classification. DocuPipe automatically detects document types and routes them to appropriate schemas - essential for processing mixed document batches.
No. Document splitting requires specialized processing that Gemini doesn't offer. DocuPipe automatically identifies document boundaries within multi-page PDFs and processes each as a separate document.
No. Gemini outputs extracted data without confidence metrics. DocuPipe provides field-level confidence scores, enabling automated routing to human review when extraction certainty is low.
DocuPipe is purpose-built for production document processing with schema enforcement, deterministic output, source traceability, confidence scores, human review, and webhooks. Gemini is a general-purpose AI assistant that can extract data but lacks the consistency and features required for production workflows.
For teams that need consistent schemas, source traceability, and production-ready features, DocuPipe is the best Gemini alternative. Gemini is a general-purpose AI assistant - fine for ad-hoc questions about a document, but not built for reliable data extraction. For anything going into a database or production system, DocuPipe's deterministic approach prevents the data quality issues that plague LLM-based extraction.


The best way to compare? Try it yourself.
Up to 20,000 free credits with an eligible work email. No credit card required.