8 min read
DocuPipe vs Nanonets: Which is best for your team? [2026]
Published February 17, 2026

Looking for the best Nanonets alternative? DocuPipe vs Nanonets comes down to flexibility. With Nanonets, you can't just hit an API endpoint with a schema - you must log into their web UI, create a model, and train it before extracting anything. Everyone on the team is locked into that dashboard paradigm. DocuPipe gives you direct API access from day one, plus Make/Zapier/n8n integrations for ops teams. Developers get code, ops gets no-code automation. No forced workflows, no model training, no waiting.
TL;DR
Nanonets requires dashboard training before API access works. DocuPipe is API-first: send a document with your schema, get JSON back. No UI workflows, no model training. Developers get direct API access; ops teams get Make, Zapier, and n8n integrations. You're not locked into one paradigm.
Table of Contents
- DocuPipe vs Nanonets at a glance
- Nanonets alternative: API-first, but ops-friendly too
- Zero-shot extraction vs model training: the core Nanonets vs DocuPipe difference
- Complex unstructured documents: where Nanonets struggles
- Nanonets pricing vs DocuPipe: hidden cliffs vs transparent credits
- Schema management: API-defined vs dashboard-locked
- Human review: source highlighting vs ops-centric workflows
- What Nanonets users actually say
- Which should you choose?
- FAQ
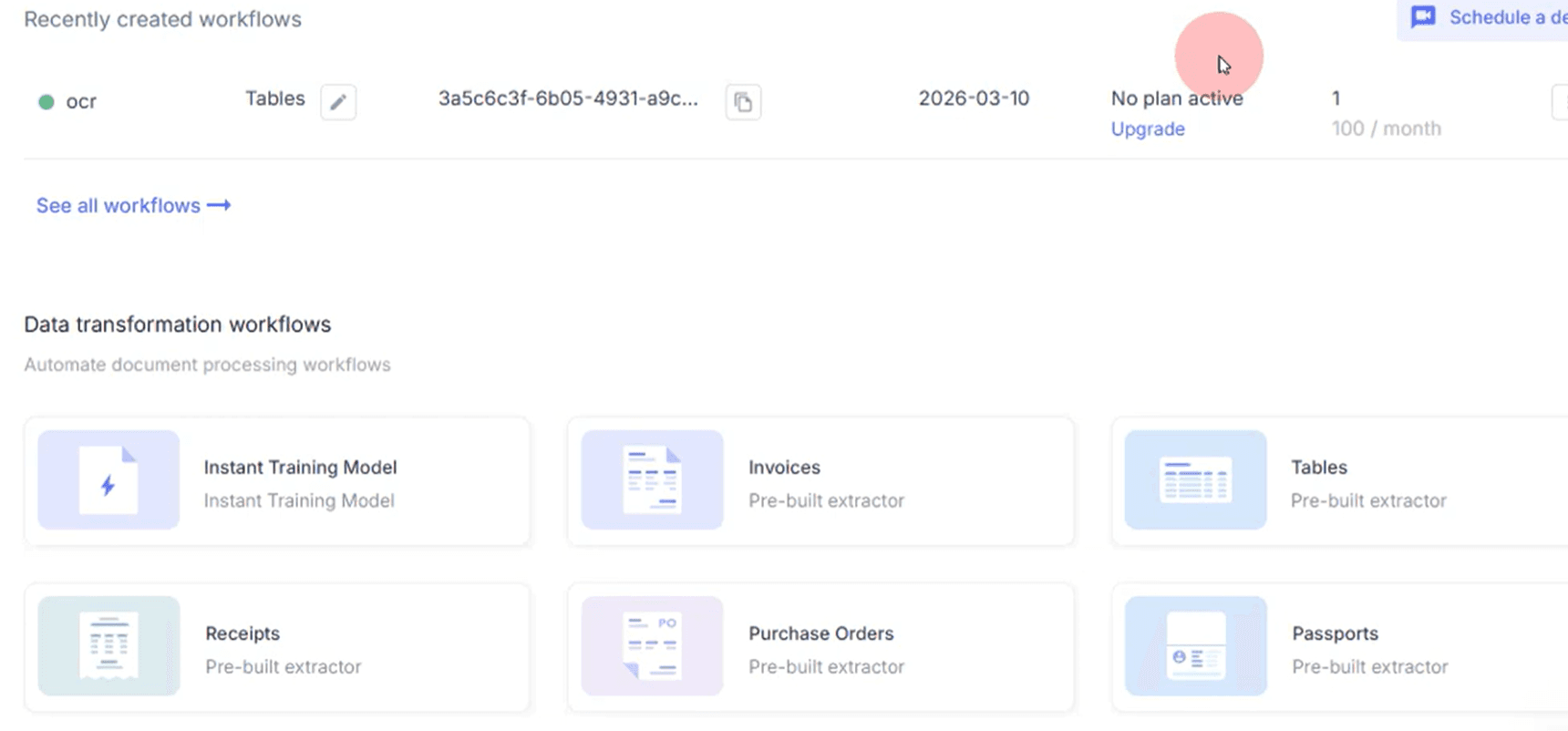
DocuPipe vs Nanonets at a glance
| DocuPipe | Nanonets | |
|---|---|---|
| Best for | Developers shipping products | Operations teams with manual workflows |
| Integration approach | API-first, hit endpoint with schema | UI-first, create models in dashboard |
| Time to first extraction | Minutes (API key + one endpoint) | Hours to days (dashboard setup + training) |
| Training required | Zero-shot extraction, no training | Must train models per document type |
| Pricing transparency | Clear credit-based pricing ($99/mo Business) | Hidden volume-based cliffs, custom quotes |
| Complex documents | Handles 2500+ page unstructured docs | Struggles with variable-length documents |
| Human review | Built-in source highlighting review UI | Review built into their ops workflow |
| Schema management | API-defined + optional dashboard | Dashboard-only model configuration |
| Compliance | SOC 2 Type II, HIPAA, ISO 27001 | SOC 2, HIPAA available |
Ready to see the difference?
Try DocuPipe free with 300 credits. No credit card required.
Nanonets alternative: API-first, but ops-friendly too
The fundamental difference between DocuPipe and Nanonets is flexibility. DocuPipe is API-first - get an API key, define your schema in the request, and start extracting documents immediately. Your engineering team can integrate document extraction into your application in hours, not days.
Nanonets takes a different approach. Before you can extract a single document via API, you must log into their dashboard, create a model, define fields through their UI, and train it with sample documents. Everyone on the team is locked into that dashboard paradigm.
DocuPipe is API-first for developers, but also connects to Make, Zapier, and n8n for ops teams that prefer no-code automation. Your engineers build the core integration; your ops team can trigger extractions and route results without writing code. You're not forced to choose between developer experience and ops accessibility.
Zero-shot extraction vs model training: the core Nanonets vs DocuPipe difference
Nanonets claims 95%+ accuracy on standard formats - but accuracy depends on training data quality. Like any trained model, performance varies based on how well your training documents represent production variations. Complex layouts, handwritten text, and degraded scans need to be well-represented in training samples, or accuracy suffers.
Nanonets requires you to train models before extraction works well. You create a model in their dashboard, upload training documents, annotate the fields you want to extract, and wait for the model to train. There's no automated optimization capabilities - everything requires manual configuration. No evaluation sets or regression testing. No workflow orchestration beyond webhooks. Missing schema versioning and human-in-the-loop review UI.
DocuPipe uses zero-shot extraction. Send a document with your schema, get structured data back. No training required. No sample documents needed. Works on day one.
Complex unstructured documents: where Nanonets struggles
Document extraction isn't just about invoices and receipts. Real-world documents are messy. A 50-page medical history. A variable-length legal contract. An insurance claim with attachments. These documents don't fit neatly into predefined templates.
Nanonets' pre-built models work well for their trained document types. But edge cases can reduce accuracy: unusual invoice formats, non-standard table layouts, handwritten annotations. Teams processing diverse documents often report spending significant time in HITL (Human-In-The-Loop) annotation cycles to reach acceptable accuracy on document types outside Nanonets' core training data.
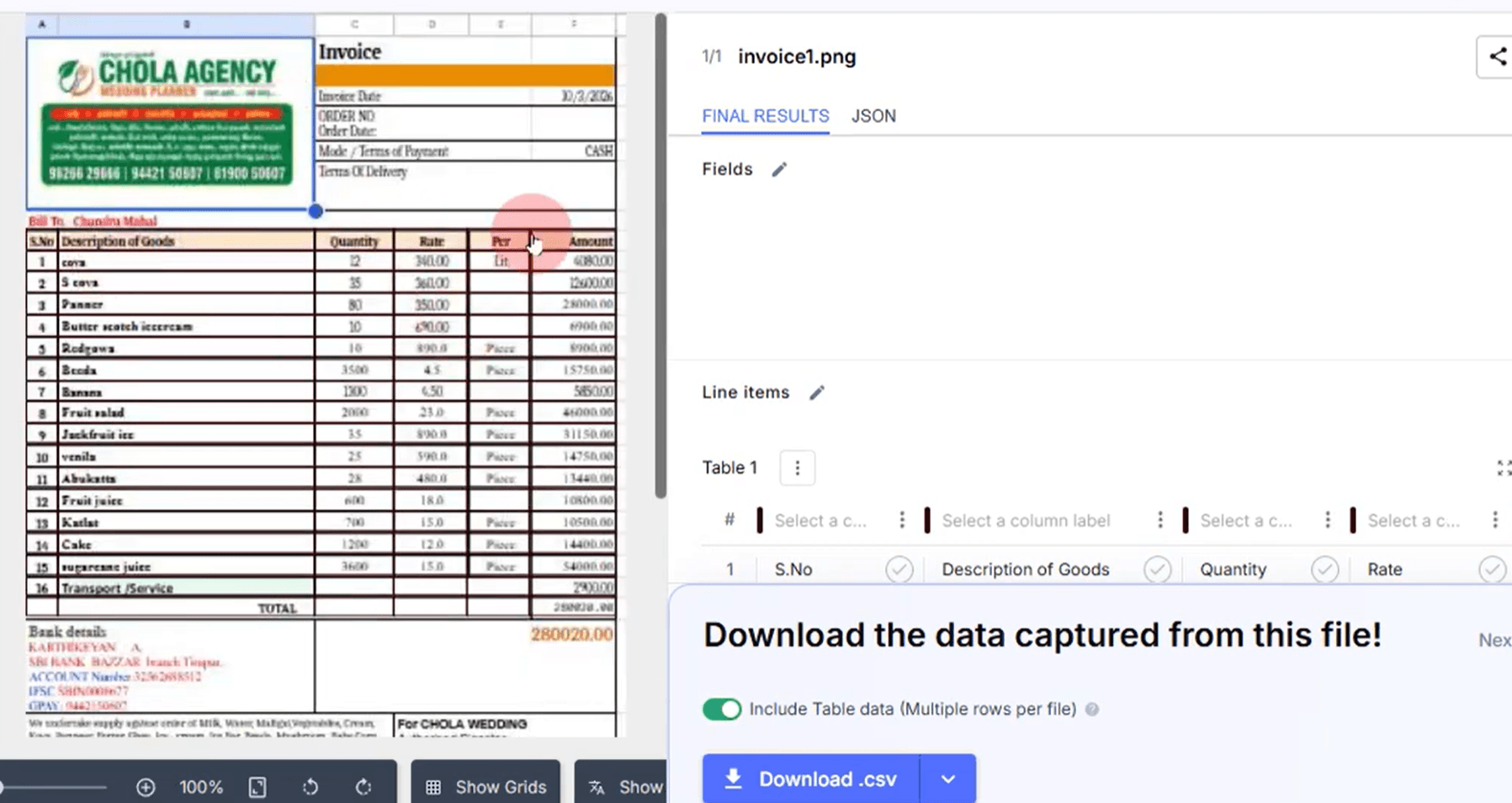
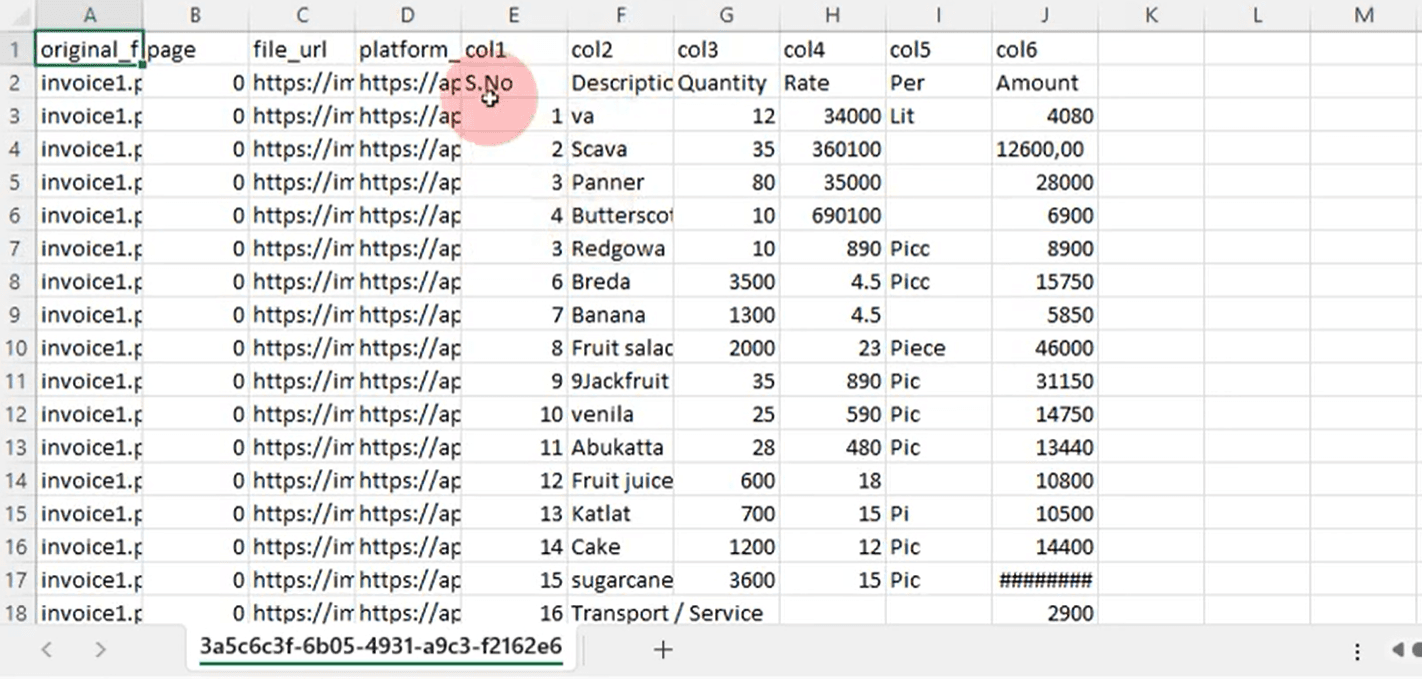
DocuPipe handles complex, variable-length documents with ease. Our intelligent document processing adapts to document structure on the fly with built-in confidence scoring. When the AI is uncertain, it tells you. When it's confident, you can trust it. No endless annotation cycles, no manual training, no HITL purgatory.
Nanonets pricing vs DocuPipe: hidden cliffs vs transparent credits
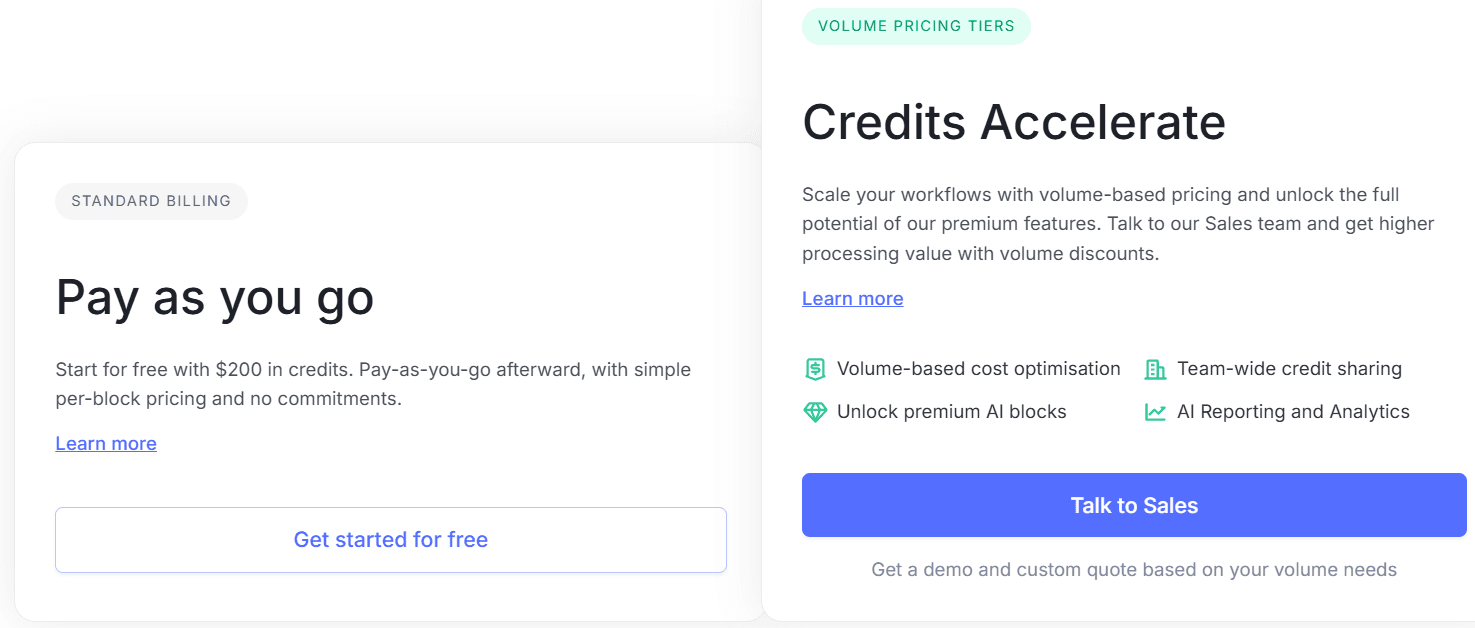
Pricing transparency is a key difference when evaluating Nanonets alternatives. DocuPipe uses a clear credit-based pricing model. Our Business plan starts at $99/month. Classification costs just 0.1 credits per page - meaning you can classify up to 25,000 pages on Business tier. Credits cover everything - extraction, review, standardization. You know exactly what you're paying before you sign up.
Nanonets uses a 'block-run' billing model that's less transparent than straightforward credit-per-document pricing. They advertise starter tiers, but as your volume grows, you hit pricing cliffs that require custom quotes. What starts as affordable can become expensive fast, and you won't know the exact cost until you're deep in a sales conversation. And by default, your data runs through their US-based, multi-tenant cloud infrastructure.
For engineering teams budgeting a project, DocuPipe's transparent pricing lets you calculate costs upfront. No surprise invoices. No volume-based cliffs. No waiting for custom quotes. Just straightforward pricing you can plan around.
See it in action
300 free credits. No credit card required.
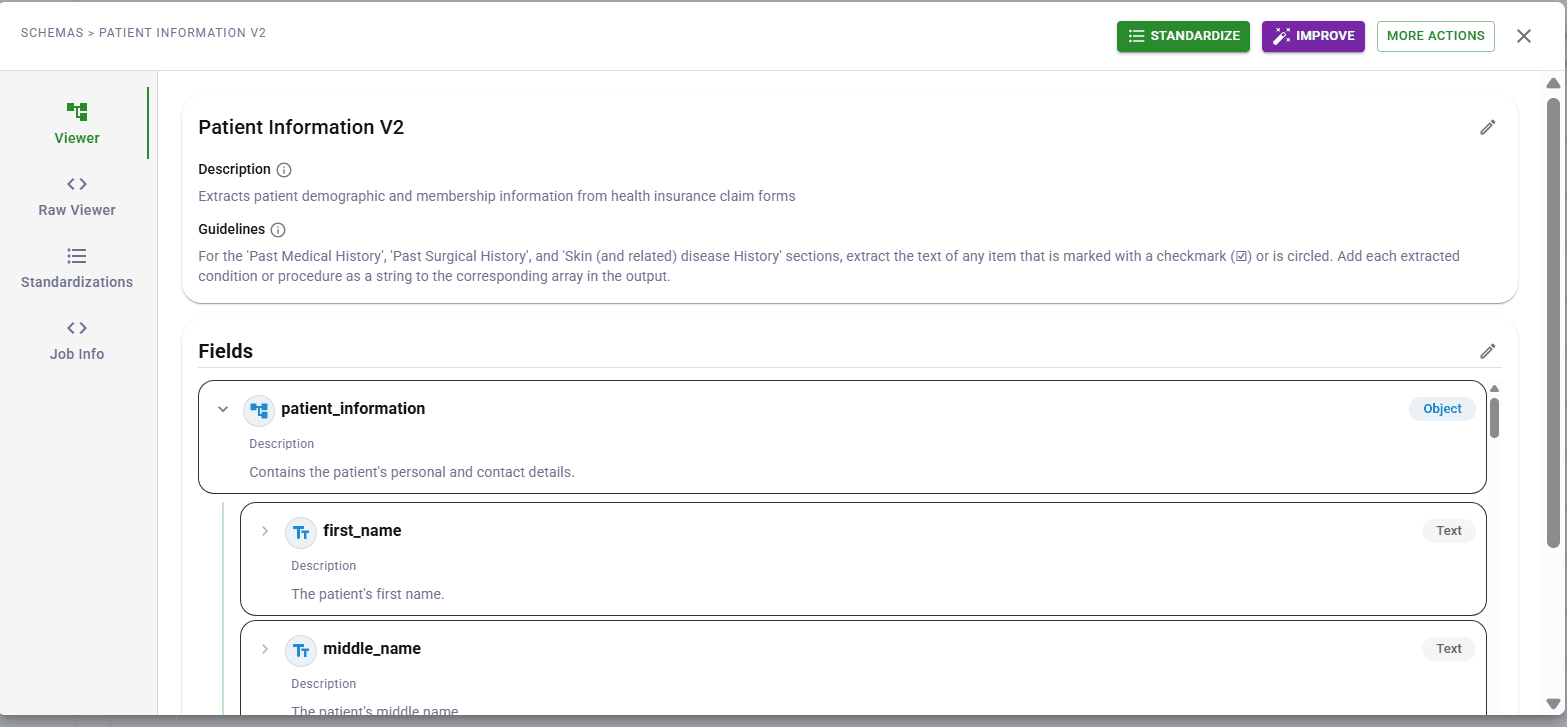
Schema management: API-defined vs dashboard-locked
How you define extraction schemas matters for developer productivity. DocuPipe lets you define schemas directly in your API calls. Change a field name? Update your code and deploy. Add a new field? Same process. Your schema lives in version control alongside your application code.
Nanonets locks schema management to their dashboard. Every field change requires logging into their UI, modifying the model, and potentially retraining. Your extraction logic lives outside your codebase, in a third-party dashboard you can't version control.
DocuPipe also offers a schema dashboard for teams that want a visual interface - but it's optional, not mandatory. Developers get API access. Ops teams get a UI. Both work together. With Nanonets, everyone is forced through the dashboard whether they want it or not.
Human review: source highlighting vs ops-centric workflows
Both DocuPipe and Nanonets offer human review interfaces, but the design philosophy differs. DocuPipe's source highlighting review UI is built for verification workflows. Click any extracted field and see exactly where it came from on the source document, highlighted in context. Your team can verify accuracy quickly.
Nanonets' review interface is designed for operations teams managing document workflows. It's comprehensive but oriented toward their dashboard-first paradigm - which means your entire team must adapt to their way of doing things.
The difference is integration. DocuPipe's review UI works alongside our API-first approach. Your engineering team builds the integration, your ops team handles review - both workflows work together. With Nanonets, the entire team must adapt to their ops-centric dashboard model.
What Nanonets users actually say
Nanonets' Gartner Peer Insights reviews are candid. One reviewer: 'A mixed bag... we had to go through some painful trial and error with the setup.' Another: 'Processing speed seems to vary wildly. Sometimes it will fly through 200 documents, and sometimes it seems to take 10 minutes for fewer than 50.' A third: 'The product has broken at inopportune times. Our clients rely on speed of service.'
DocuPipe doesn't break at inopportune times. We hold a 4.9/5 on G2. One customer processes thousands of handwritten forms at 98% reliability. Another went from reading our API docs to a working system in under an hour.
Which should you choose?
Choose DocuPipe if...
You're a developer who wants direct API access
You want to ship document extraction in hours, not days
You need zero-shot extraction without training models
You process complex, variable-length unstructured documents
You want transparent, predictable pricing
You prefer schema definitions in code, not dashboards
You need on-premise deployment for data residency
Choose Nanonets if...
You're an operations team that prefers point-and-click interfaces
You process templated documents with consistent formats
You want built-in workflow automation tools
You're comfortable with volume-based pricing and custom quotes
You prefer visual model building over code-based schemas
Skip the setup headaches
Start extracting documents in minutes, not weeks.
Frequently asked questions
Not really. While Nanonets has an API, you must first create and train models through their web dashboard before the API works. You can't just hit an endpoint with a schema and get structured data back. DocuPipe is different - direct API access from day one, no dashboard setup required. This is why developers looking for a Nanonets alternative often choose DocuPipe.
Nanonets targets operations teams processing high volumes of templated documents with consistent formats - think AP departments processing thousands of identical invoices. If you fit that narrow profile and prefer dashboards over APIs, Nanonets exists for that use case. Most modern teams need more flexibility.
DocuPipe works accurately out of the box with zero-shot extraction - no training required. Nanonets requires training with sample documents to improve accuracy for your specific document types. For teams that want immediate results without training, DocuPipe delivers.
No. DocuPipe uses zero-shot extraction. Define your schema, send a document, get structured data back. No model training, no sample documents, no waiting. This is the core difference between DocuPipe and Nanonets - we're built for developers who want to ship code, not train models.
DocuPipe uses transparent credit-based pricing starting at $99/month for our Business plan. Nanonets uses volume-based pricing with tiers that require custom quotes as you scale. Many teams find Nanonets pricing unclear until they're deep in a sales conversation. If predictable pricing matters, DocuPipe is the Nanonets alternative with transparent costs.
Nanonets works best with templated documents that follow consistent patterns. For variable-length documents like 50-page medical histories or complex legal contracts, the training-based approach struggles. DocuPipe handles complex, unstructured documents with zero-shot extraction - no templates required.
Most teams finish migrating from Nanonets to DocuPipe in a day or two. The main work is replacing Nanonets API calls with DocuPipe document extraction API calls and moving your schema definitions into code. We're happy to help guide you through the migration process.
Yes. DocuPipe is SOC 2 Type II certified and ISO 27001 compliant. We sign BAAs for healthcare customers processing PHI. For organizations with the strictest data requirements, on-premise deployment keeps everything inside your own infrastructure.
DocuPipe is built specifically for developers who want API-first document extraction. Direct endpoint access, schema-defined in code, zero-shot extraction with no training. If you're an engineering team that wants to ship code instead of clicking through dashboards, DocuPipe is the Nanonets alternative designed for you.
Yes, but it's optional. DocuPipe offers a schema dashboard and source highlighting review UI for teams that want visual interfaces. The difference is you're not forced to use them. Developers can work entirely through the API while ops teams use the dashboard. With Nanonets, everyone must go through the dashboard.




The best way to compare? Try it yourself.
300 free credits. No credit card required.